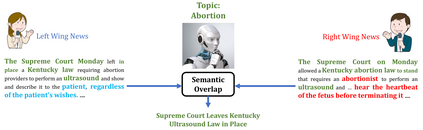
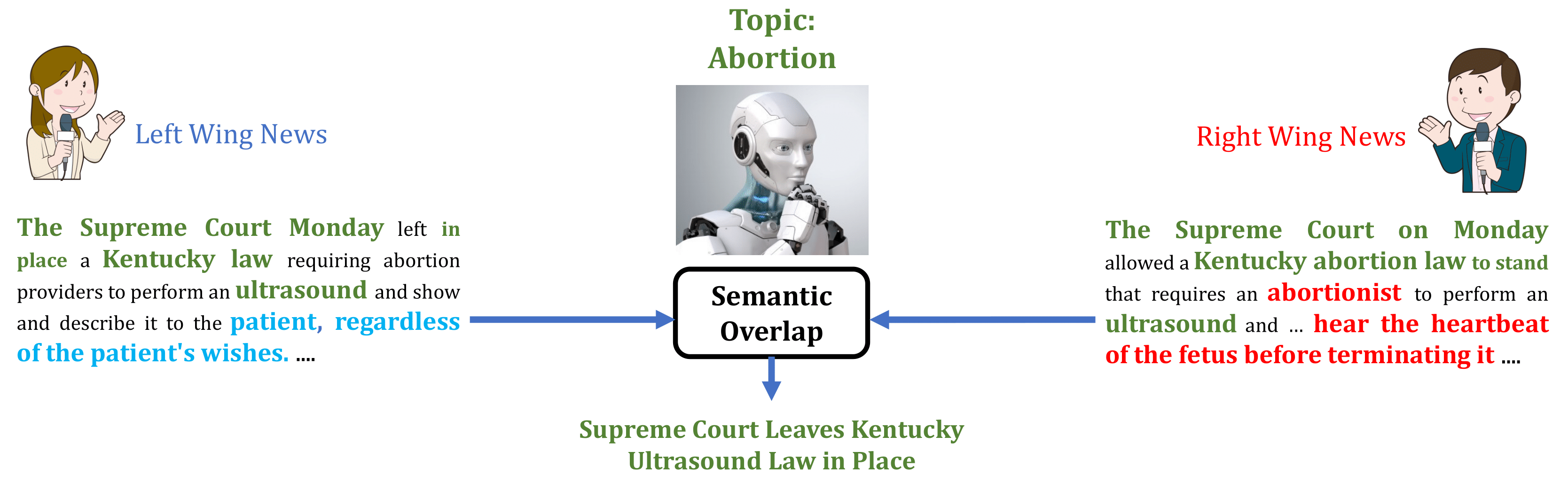
In this paper, we introduce an important yet relatively unexplored NLP task called Multi-Narrative Semantic Overlap (MNSO), which entails generating a Semantic Overlap of multiple alternate narratives. As no benchmark dataset is readily available for this task, we created one by crawling 2,925 narrative pairs from the web and then, went through the tedious process of manually creating 411 different ground-truth semantic overlaps by engaging human annotators. As a way to evaluate this novel task, we first conducted a systematic study by borrowing the popular ROUGE metric from text-summarization literature and discovered that ROUGE is not suitable for our task. Subsequently, we conducted further human annotations/validations to create 200 document-level and 1,518 sentence-level ground-truth labels which helped us formulate a new precision-recall style evaluation metric, called SEM-F1 (semantic F1). Experimental results show that the proposed SEM-F1 metric yields higher correlation with human judgement as well as higher inter-rater-agreement compared to ROUGE metric.
翻译:在本文中,我们引入了一项重要但相对未探索的NLP任务,即多语义拼写重叠(MNSO),这需要产生多种替代叙述的语义重叠。由于目前无法为这项任务提供基准数据集,我们从网络上采集了2,925对叙事对,随后,我们经历了人工创造411个不同地真义语义重叠的繁琐过程,让人类旁观者参与其中。作为评估这一新任务的一种方式,我们首先通过从文本摘要文献中借用广受欢迎的ROUGE指标进行了系统研究,发现ROUGE不适合我们的任务。随后,我们进行了进一步的人类说明/估价,以创建200个文件级和1,518个判决级地真义标签,帮助我们制定了一个新的精确-应答风格评价指标,称为SEM-F1(smantict F1)。 实验结果表明,拟议的SEM-F1指标与人类判断具有更高的相关性,与ROUGE衡量标准相比,以及更高的内部协定。