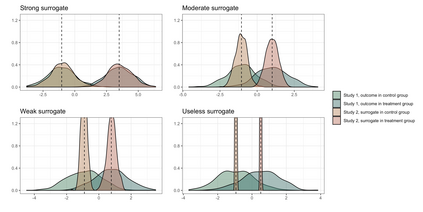
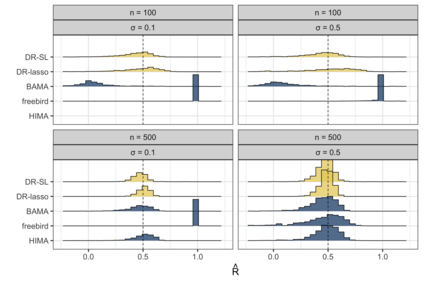
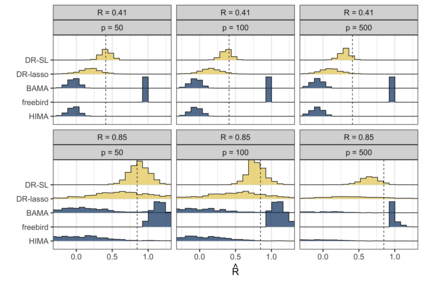
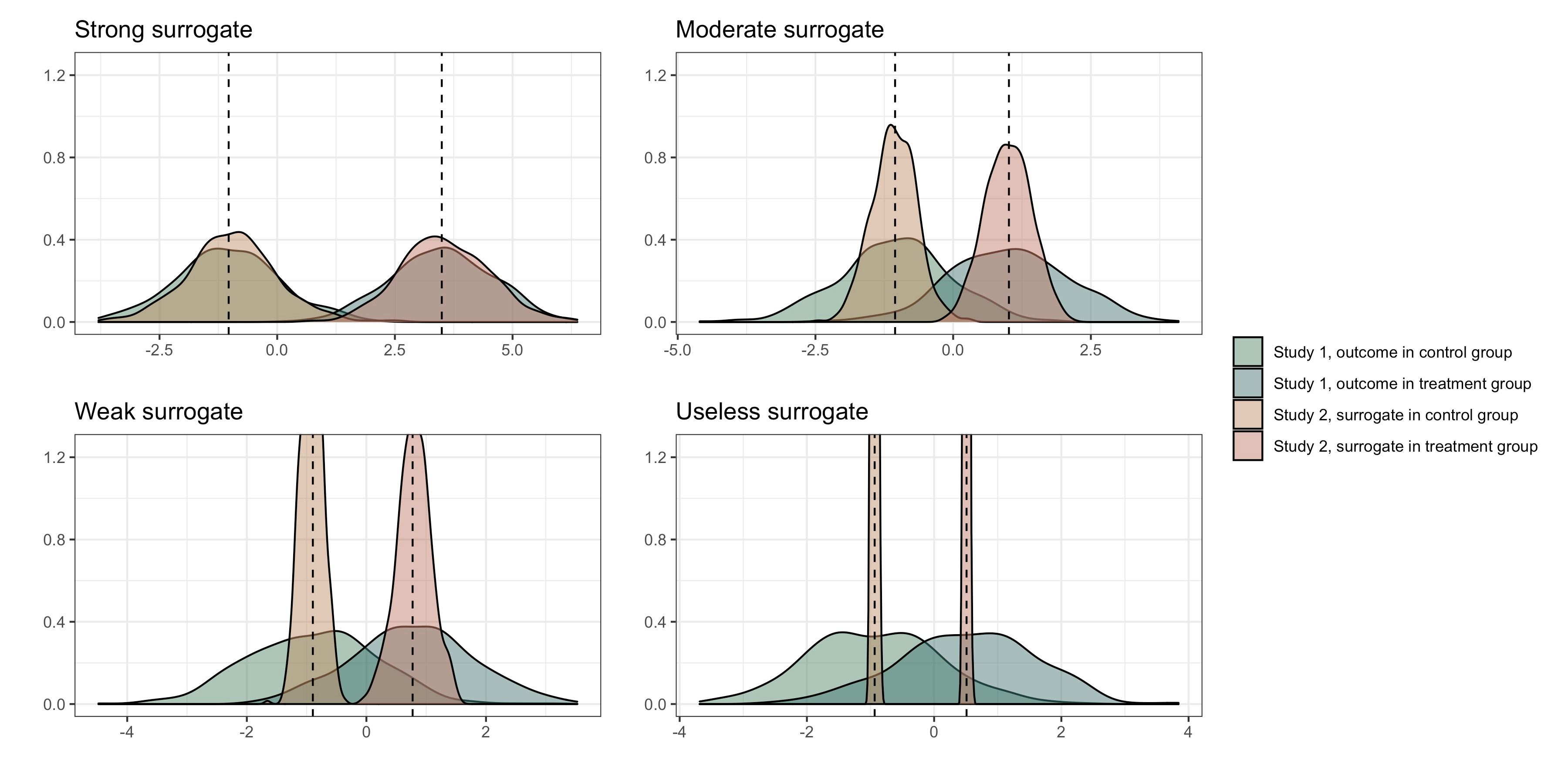
When evaluating the effectiveness of a treatment, policy, or intervention, the desired measure of effectiveness may be expensive to collect, not routinely available, or may take a long time to occur. In these cases, it is sometimes possible to identify a surrogate outcome that can more easily/quickly/cheaply capture the effect of interest. Theory and methods for evaluating the strength of surrogate markers have been well studied in the context of a single surrogate marker measured in the course of a randomized clinical study. However, methods are lacking for quantifying the utility of surrogate markers when the dimension of the surrogate grows and/or when study data are observational. We propose an efficient nonparametric method for evaluating high-dimensional surrogate markers in studies where the treatment need not be randomized. Our approach draws on a connection between quantifying the utility of a surrogate marker and the most fundamental tools of causal inference -- namely, methods for estimating the average treatment effect. We show that recently developed methods for incorporating machine learning methods into the estimation of average treatment effects can be used for evaluating surrogate markers. This allows us to derive limiting asymptotic distributions for key quantities, and we demonstrate their good performance in simulation.
翻译:在评估一种治疗、政策或干预的有效性时,所期望的效能衡量标准可能昂贵,收集费用昂贵,无法经常获得,或可能需要很长时间才能出现。在这些情况下,有时有可能确定一种替代结果,这种替代结果可以更容易/快速/捷捷地捕捉到利益的效果。我们的方法是在随机临床研究过程中测量的单一替代标记中仔细研究的,评价代用标记的强度的理论和方法。然而,在代用代用标记的尺寸增长和/或研究数据为观察性的时,缺乏量化代用标记效用的方法。我们建议一种有效的非参数方法,用于在不需要随机处理的研究中评价高维代用代用标记。我们的方法借鉴了将代用标记的效用量化与因果关系的最根本工具 -- -- 即估计平均治疗效果的方法 -- -- 之间的关联。我们表明,在评估代用代用标记时,可以使用最近开发的机器学习方法来估计平均治疗效果,用于评估代用代用标记的尺寸和/或研究数据是观察性的。我们提出了一种有效的非参数方法,用于评价高维代用代用代用标记的代用标记,在不需要随机处理的试验时,这样可以使我们在模拟中得出良好的性中进行质量上。