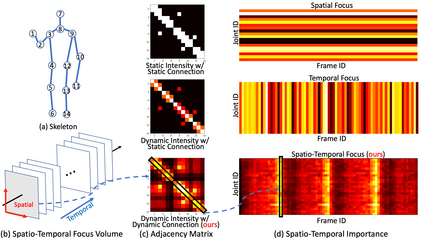
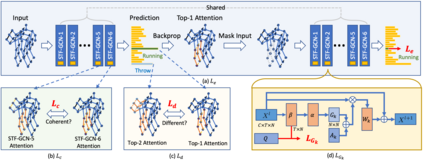
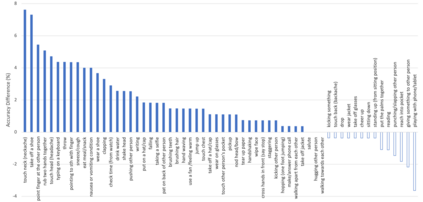
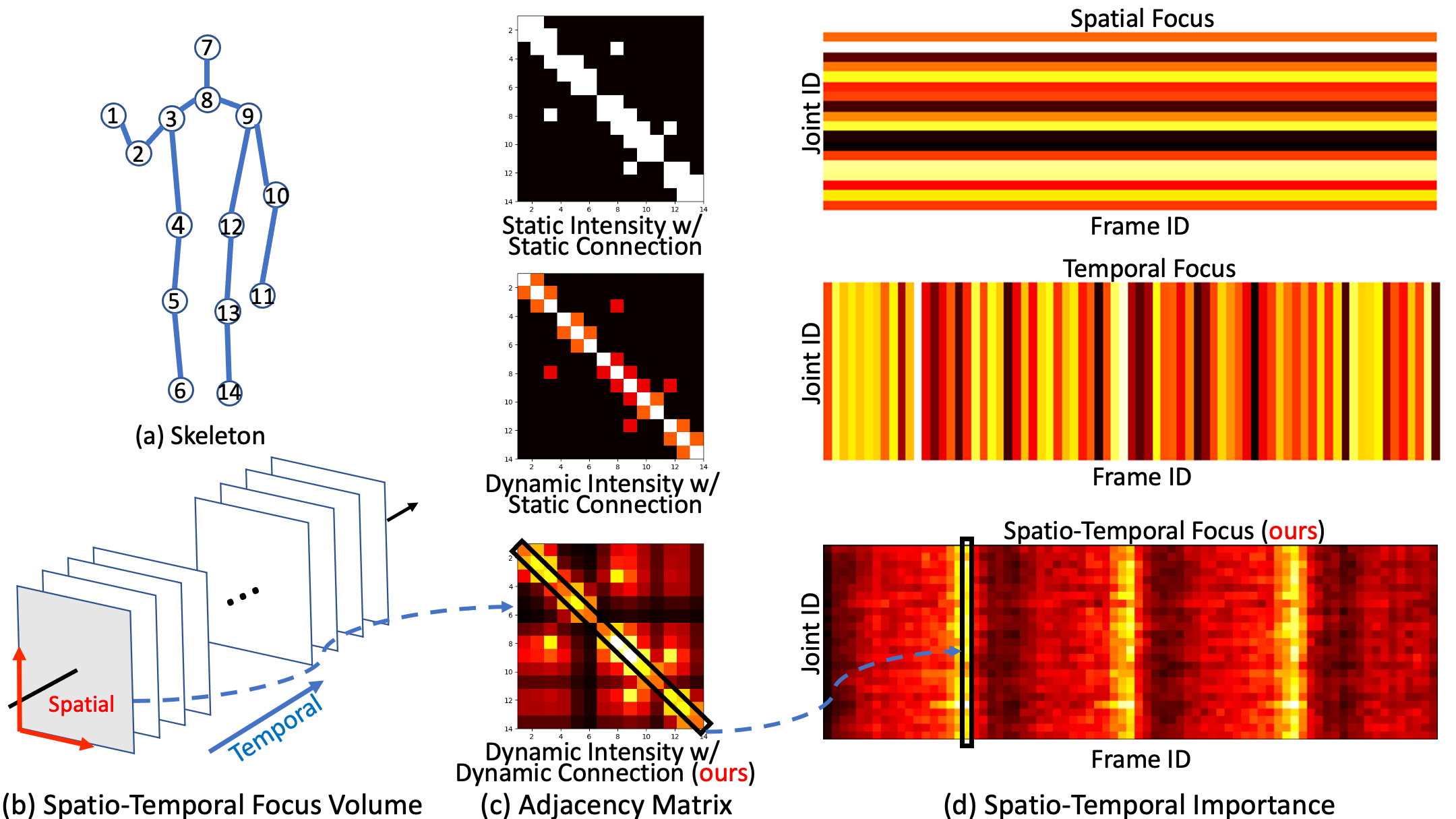
Graph Convolutional Networks (GCNs) have been widely used to model the high-order dynamic dependencies for skeleton-based action recognition. Most existing approaches do not explicitly embed the high-order spatio-temporal importance to joints' spatial connection topology and intensity, and they do not have direct objectives on their attention module to jointly learn when and where to focus on in the action sequence. To address these problems, we propose the To-a-T Spatio-Temporal Focus (STF), a skeleton-based action recognition framework that utilizes the spatio-temporal gradient to focus on relevant spatio-temporal features. We first propose the STF modules with learnable gradient-enforced and instance-dependent adjacency matrices to model the high-order spatio-temporal dynamics. Second, we propose three loss terms defined on the gradient-based spatio-temporal focus to explicitly guide the classifier when and where to look at, distinguish confusing classes, and optimize the stacked STF modules. STF outperforms the state-of-the-art methods on the NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400 datasets in all 15 settings over different views, subjects, setups, and input modalities, and STF also shows better accuracy on scarce data and dataset shifting settings.
翻译:为了解决这些问题,我们广泛使用图-T Spatio-Temporal Focus(GCNs)来模拟基于骨骼的动作识别的高顺序动态依赖性(GCNs),大多数现有办法并未明确将高阶时空对联合空间连接表层学和强度的重要性嵌入高阶空间连接表层和强度,而且它们也没有直接的目标,即关注模块,以在行动序列中共同学习何时和在何处应重点关注的问题。为了解决这些问题,我们建议了T-a-T Spatio-Timal Formal Focus(STF),一个基于400个基于骨架的行动识别框架,利用时空梯度梯度梯度来重点关注相关的时空特征。我们首先建议了具有可学习性梯度增强和因实例而依赖的相近度矩阵模块模块,用于模拟高阶调时空动态。第二,我们提议了三个损失术语,即基于梯度的调调调调调调点,以明确指导分类者,区分混淆的等级和优化堆叠的STF模块。