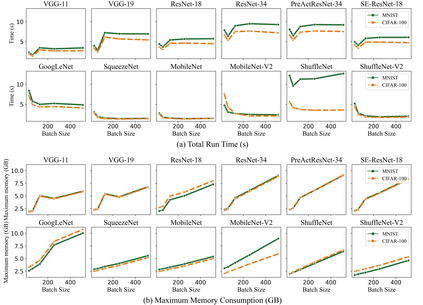
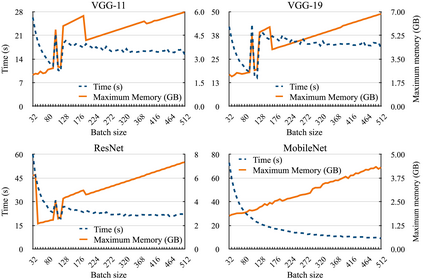
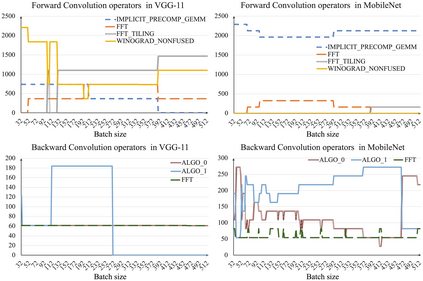
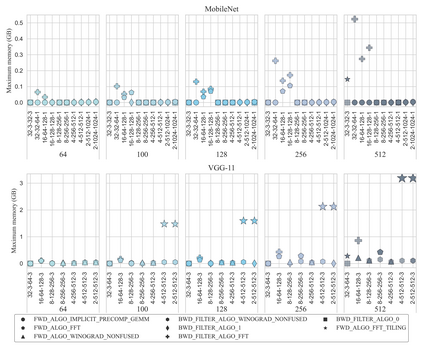
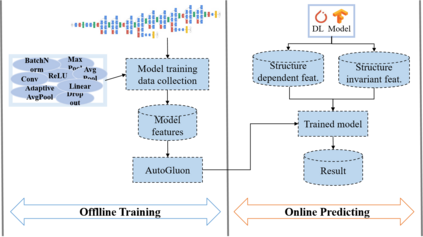
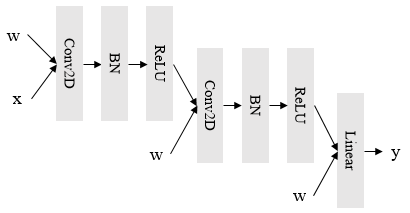
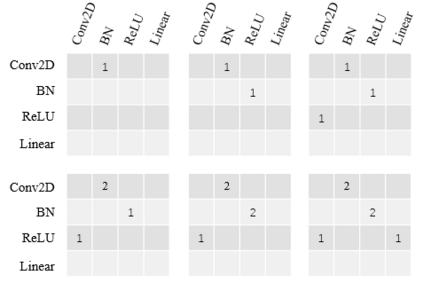
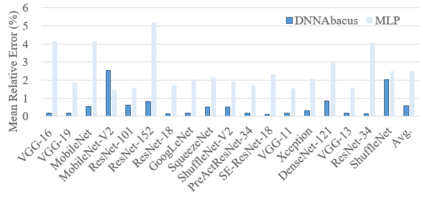
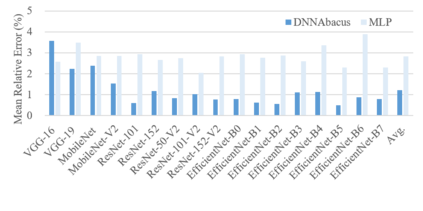
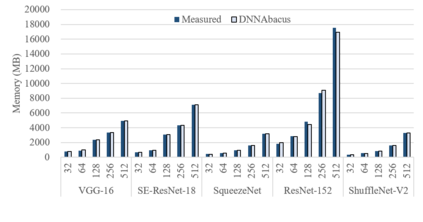
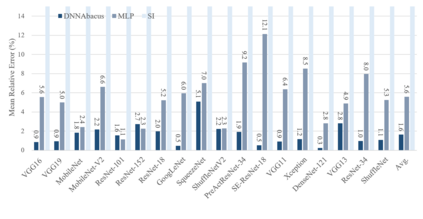
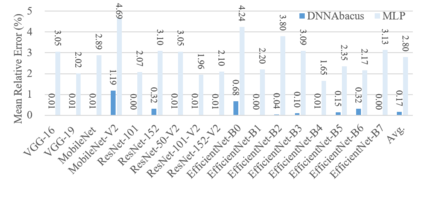
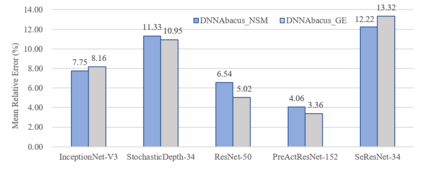
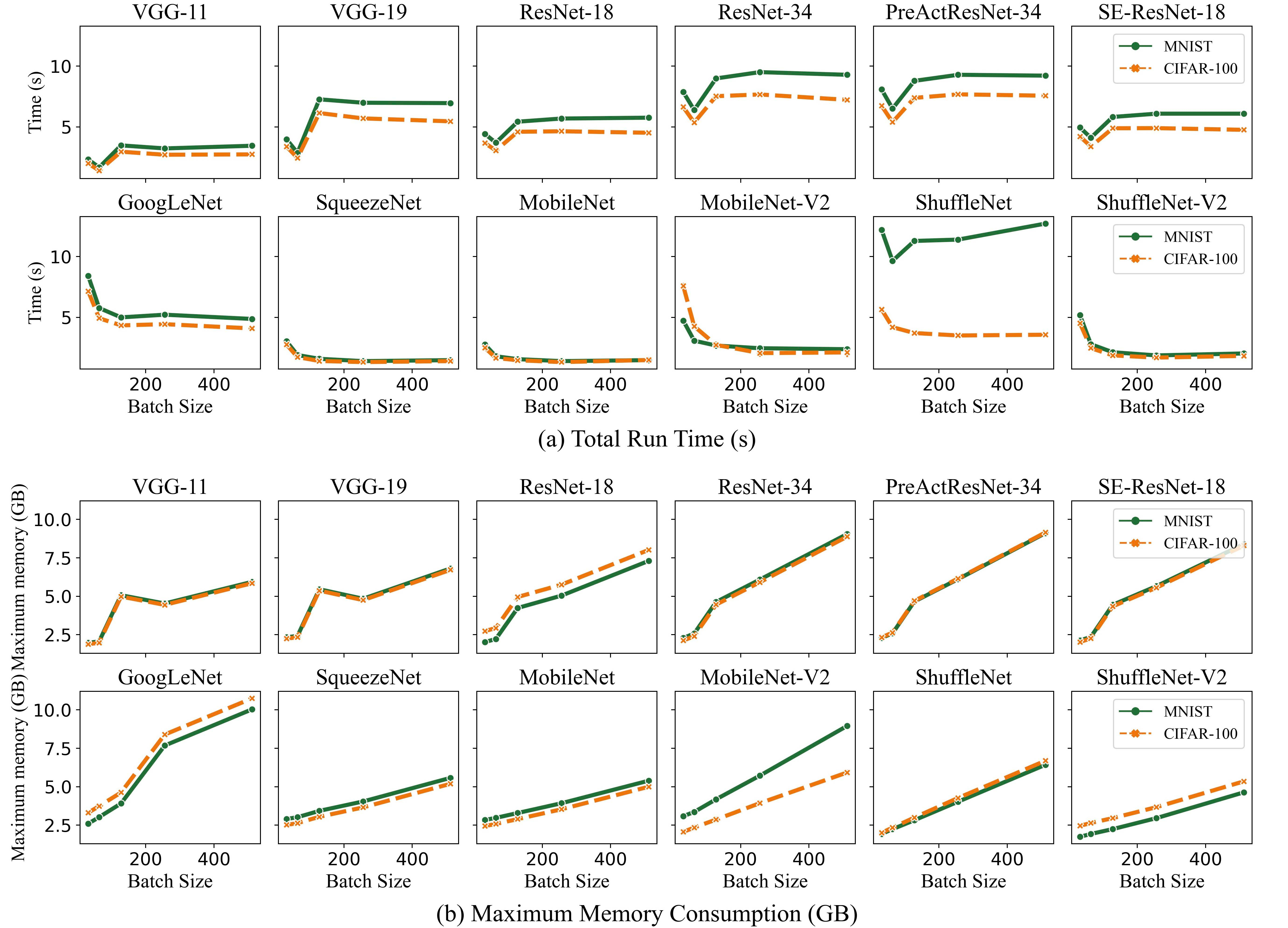
Deep learning is attracting interest across a variety of domains, including natural language processing, speech recognition, and computer vision. However, model training is time-consuming and requires huge computational resources. Existing works on the performance prediction of deep neural networks, which mostly focus on the training time prediction of a few models, rely on analytical models and result in high relative errors. %Optimizing task scheduling and reducing job failures in data centers are essential to improve resource utilization and reduce carbon emissions. This paper investigates the computational resource demands of 29 classical deep neural networks and builds accurate models for predicting computational costs. We first analyze the profiling results of typical networks and demonstrate that the computational resource demands of models with different inputs and hyperparameters are not obvious and intuitive. We then propose a lightweight prediction approach DNNAbacus with a novel network structural matrix for network representation. DNNAbacus can accurately predict both memory and time cost for PyTorch and TensorFlow models, which is also generalized to different hardware architectures and can have zero-shot capability for unseen networks. Our experimental results show that the mean relative error (MRE) is 0.9% with respect to time and 2.8% with respect to memory for 29 classic models, which is much lower than the state-of-the-art works.
翻译:深层学习吸引了各方面的兴趣,包括自然语言处理、语音识别和计算机愿景。然而,模型培训耗时费时,需要大量计算资源。深神经网络的现有性能预测工作,主要侧重于对几个模型的培训时间预测,依赖分析模型,并导致高相对错误。%优化任务时间安排和减少数据中心的工作失败对于改善资源利用和减少碳排放至关重要。本文件调查29个古老的深层神经网络的计算资源需求,并为预测计算成本建立准确的模型。我们首先分析典型网络的特征分析结果,并表明具有不同投入和超光谱的模型的计算资源需求并不明显和直观。然后我们提出轻量的DNNNAbacus预测方法,配有网络代表的新颖的网络结构矩阵。 DNNNAbacus可以准确预测PyTorrch和TensorFlow模型的记忆和时间成本。这些模型同样被广泛分为不同的硬件结构,并且可以拥有对无形网络的零射能力。我们的实验结果显示,使用不同输入和超光度的模型的中值相对错误(MRE)比2.8的模型为0.8%。