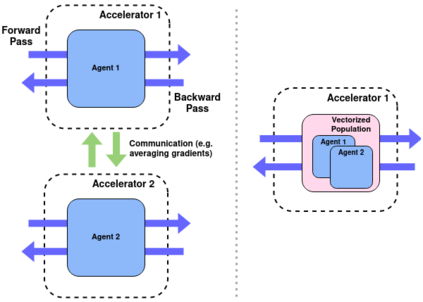
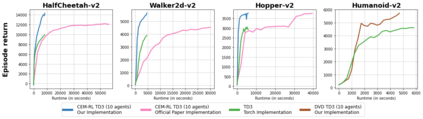
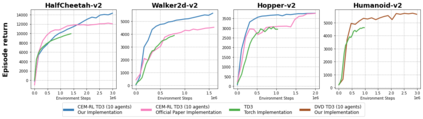
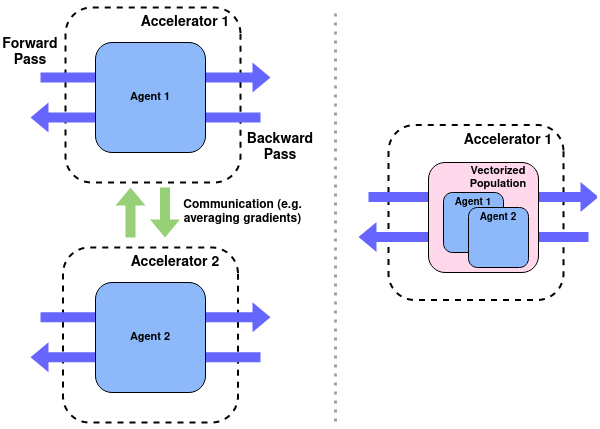
Training populations of agents has demonstrated great promise in Reinforcement Learning for stabilizing training, improving exploration and asymptotic performance, and generating a diverse set of solutions. However, population-based training is often not considered by practitioners as it is perceived to be either prohibitively slow (when implemented sequentially), or computationally expensive (if agents are trained in parallel on independent accelerators). In this work, we compare implementations and revisit previous studies to show that the judicious use of compilation and vectorization allows population-based training to be performed on a single machine with one accelerator with minimal overhead compared to training a single agent. We also show that, when provided with a few accelerators, our protocols extend to large population sizes for applications such as hyperparameter tuning. We hope that this work and the public release of our code will encourage practitioners to use population-based learning more frequently for their research and applications.
翻译:培训人员在加强学习以稳定培训、改善勘探和无药可治的绩效以及产生一套不同的解决方案方面表现出巨大的希望,然而,实践者往往不考虑以人口为基础的培训,因为人们认为这种培训过于缓慢(如果按顺序实施),或者计算成本很高(如果代理人员在独立加速器上同时接受培训)。在这项工作中,我们比较了执行情况,并重新审视了以往的研究,以表明明智地使用编集和病媒化使人口为基础的培训得以在一台机器上进行,该机器只有一台加速器,与培训单一代理相比,管理费用最低。我们还表明,在提供几台加速器时,我们的协议将扩大到大型人口规模的应用,例如超光谱调。 我们希望,这项工作和我们守则的公开发布将鼓励从业人员更经常地利用以人口为基础的学习来进行研究和应用。