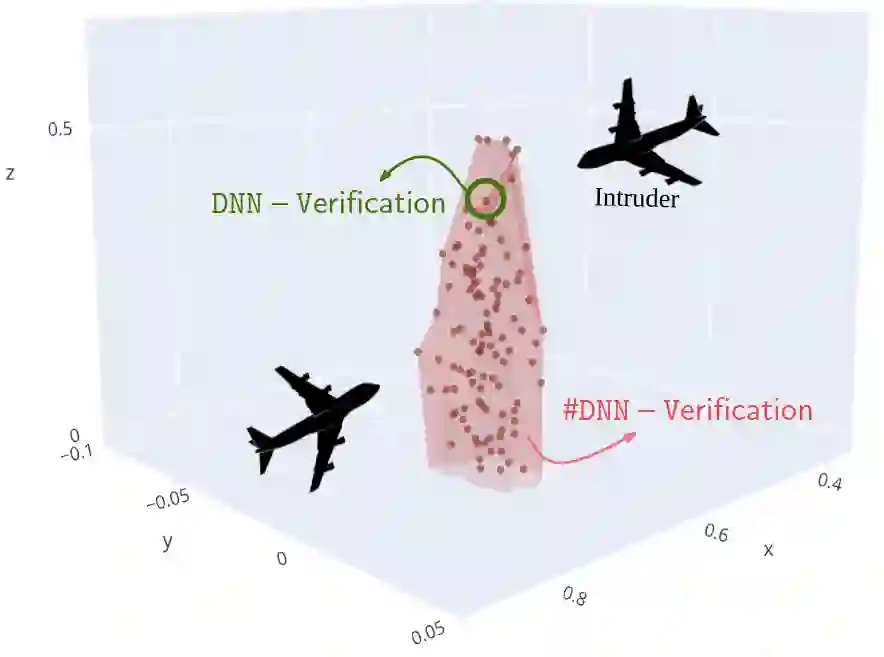
Deep Neural Networks are increasingly adopted in critical tasks that require a high level of safety, e.g., autonomous driving. While state-of-the-art verifiers can be employed to check whether a DNN is unsafe w.r.t. some given property (i.e., whether there is at least one unsafe input configuration), their yes/no output is not informative enough for other purposes, such as shielding, model selection, or training improvements. In this paper, we introduce the #DNN-Verification problem, which involves counting the number of input configurations of a DNN that result in a violation of a particular safety property. We analyze the complexity of this problem and propose a novel approach that returns the exact count of violations. Due to the #P-completeness of the problem, we also propose a randomized, approximate method that provides a provable probabilistic bound of the correct count while significantly reducing computational requirements. We present experimental results on a set of safety-critical benchmarks that demonstrate the effectiveness of our approximate method and evaluate the tightness of the bound.
翻译:深度神经网络越来越多地被采纳于需要高度安全的关键任务中,例如,自主驾驶。尽管可以使用最先进的验证员来检查DNN是否不安全(例如,是否至少有一个不安全输入配置)某些特定属性(即,是否至少有一个不安全输入配置),但是它们的是/不输出对于保护、模型选择或培训改进等其他目的而言不够丰富。在本文中,我们引入#DNNN-验证问题,其中涉及计算导致违反特定安全属性的DNN输入配置数量。我们分析这一问题的复杂性并提出一种新颖的方法,用以返回准确的违规数字。由于问题的#P完整性,我们还提出了一个随机化的大致方法,提供正确计数的可辨识性概率约束,同时大大减少计算要求。我们提出一套安全临界基准的实验结果,以显示我们大致方法的有效性并评估约束的紧凑性。