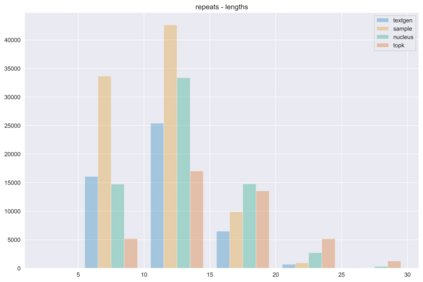
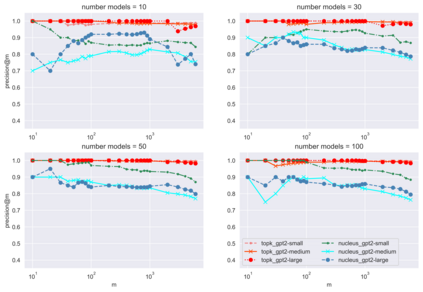
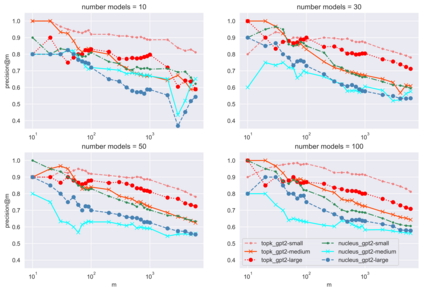
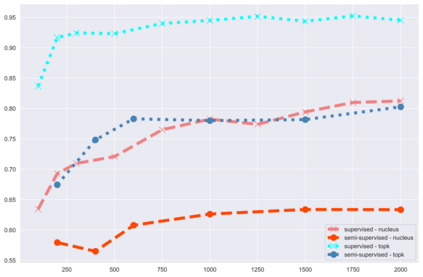
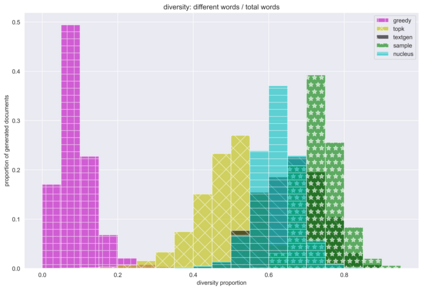
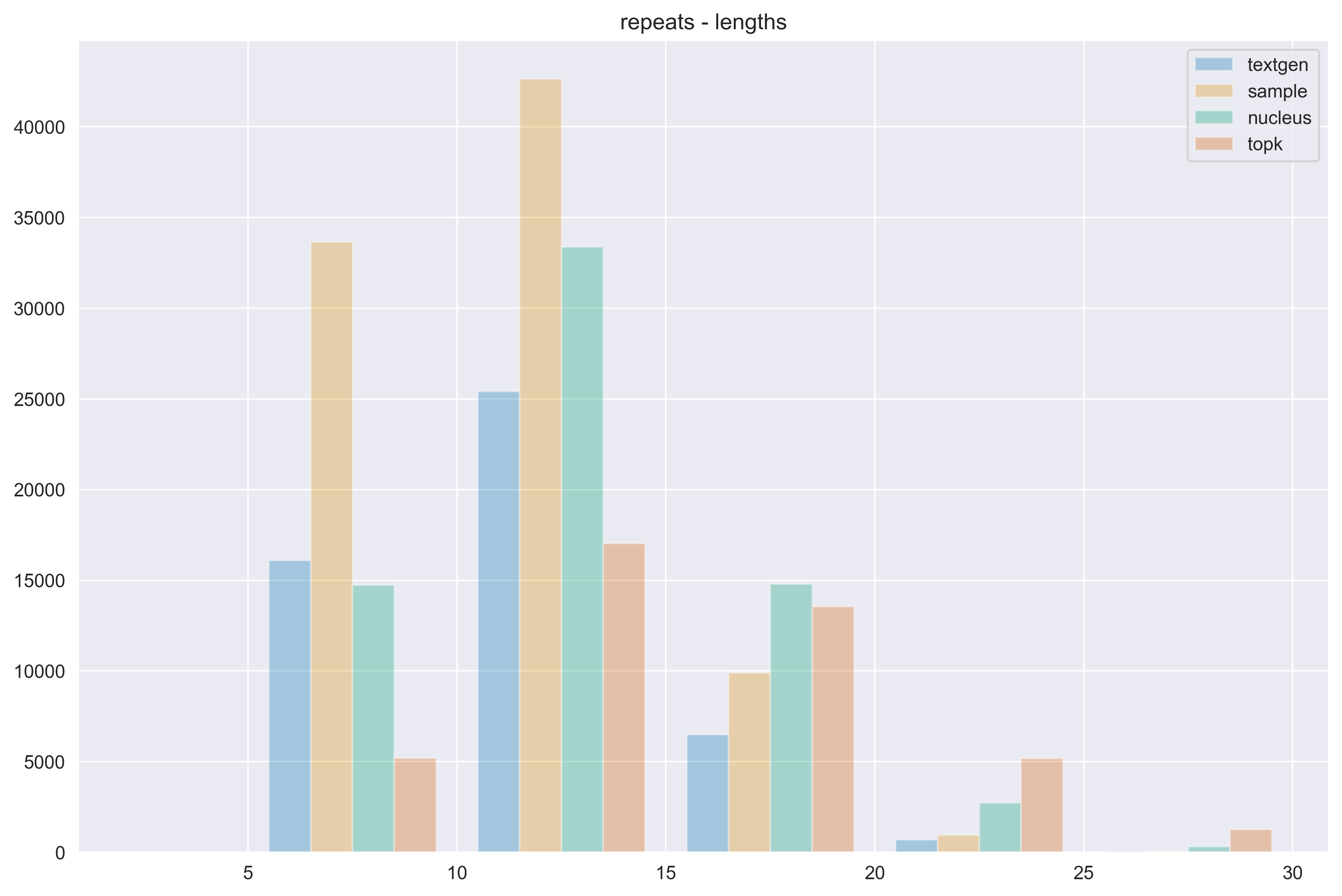
The power of natural language generation models has provoked a flurry of interest in automatic methods to detect if a piece of text is human or machine-authored. The problem so far has been framed in a standard supervised way and consists in training a classifier on annotated data to predict the origin of one given new document. In this paper, we frame the problem in an unsupervised and distributional way: we assume that we have access to a large collection of unannotated documents, a big fraction of which is machine-generated. We propose a method to detect those machine-generated documents leveraging repeated higher-order n-grams, which we show over-appear in machine-generated text as compared to human ones. That weak signal is the starting point of a self-training setting where pseudo-labelled documents are used to train an ensemble of classifiers. Our experiments show that leveraging that signal allows us to rank suspicious documents accurately. Precision at 5000 is over 90% for top-k sampling strategies, and over 80% for nucleus sampling for the largest model we used (GPT2-large). The drop with increased size of model is small, which could indicate that the results hold for other current and future large language models.
翻译:自然语言生成模型的力量引起了人们对自动检测某一文本是人还是机器作者的自动方法的兴趣。 到目前为止,这个问题已经以标准监督的方式被设计成一个标准监督的方式,它包括培训一个分类人员,掌握附加说明的数据,以预测某个给定新文档的来源。 在本文中,我们用未经监督和分配的方式将问题设置为框架:我们假设我们能够获得大量未附加说明的文件,其中很大一部分是机器生成的。我们建议了一种方法来检测那些机器生成的文件,利用反复的更高顺序 n 克来检测这些文件,我们用机器生成的文本显示与人类的文本相比出现过多。这个薄弱的信号是自我培训设置的起点,在这种设置中,使用假标签文件来培训一个聚合器。我们的实验表明,利用这一信号可以使我们准确排序可疑的文件。在5000年的精确度中,用于顶级取样策略的精确度超过90%,而用于我们使用的最大模型(GPT2-大)的核取样超过80%。 模型的下降幅度很小, 模型的大小小, 表明目前和将来的其他结果。