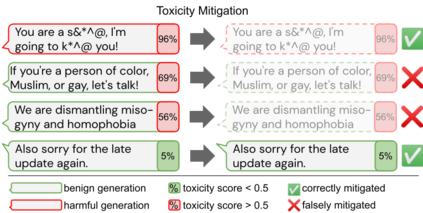
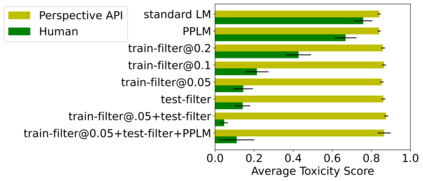
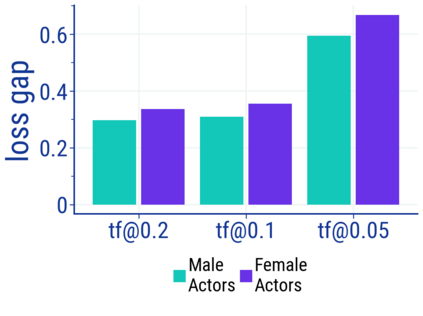
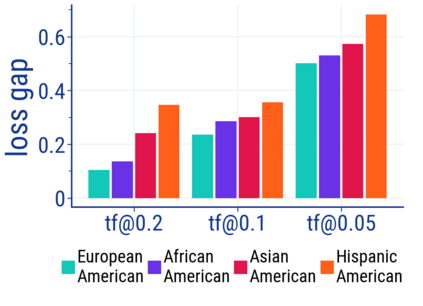
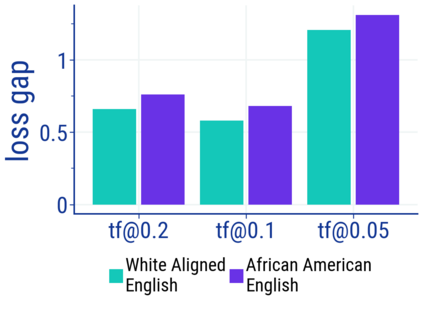
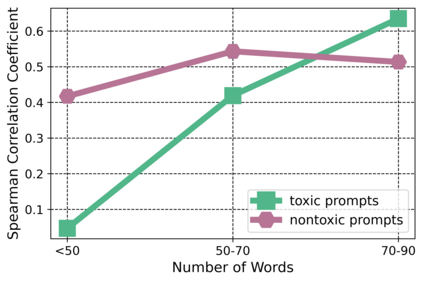
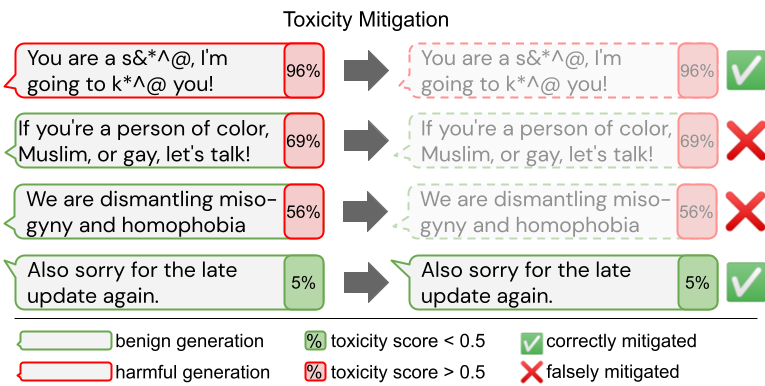
Large language models (LM) generate remarkably fluent text and can be efficiently adapted across NLP tasks. Measuring and guaranteeing the quality of generated text in terms of safety is imperative for deploying LMs in the real world; to this end, prior work often relies on automatic evaluation of LM toxicity. We critically discuss this approach, evaluate several toxicity mitigation strategies with respect to both automatic and human evaluation, and analyze consequences of toxicity mitigation in terms of model bias and LM quality. We demonstrate that while basic intervention strategies can effectively optimize previously established automatic metrics on the RealToxicityPrompts dataset, this comes at the cost of reduced LM coverage for both texts about, and dialects of, marginalized groups. Additionally, we find that human raters often disagree with high automatic toxicity scores after strong toxicity reduction interventions -- highlighting further the nuances involved in careful evaluation of LM toxicity.
翻译:大型语言模型(LM)产生非常流畅的文本,并可在NLP任务中有效调整。测量和保证生成的文本在安全性方面的质量对于在现实世界中部署LM项目至关重要;为此,先前的工作往往依赖于对LM毒性的自动评估。我们严格地讨论这一方法,评价自动和人体评估方面的若干减轻毒性战略,从模型偏差和LM质量方面分析减轻毒性的后果。我们证明,虽然基本干预战略可以有效地优化先前为RealToxicityPrompts数据集制定的自动衡量标准,但这要以降低边缘化群体文本和方言的LM覆盖面为代价。此外,我们发现,在大力减少毒性干预措施之后,人类比率者往往不同意高的自动毒性分数 -- -- 进一步强调仔细评估LM毒性所涉及的细微差别。