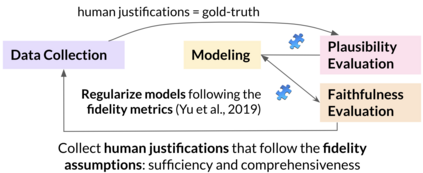
Explainable NLP (ExNLP) has increasingly focused on collecting human-annotated textual explanations. These explanations are used downstream in three ways: as data augmentation to improve performance on a predictive task, as supervision to train models to produce explanations for their predictions, and as a ground-truth to evaluate model-generated explanations. In this review, we identify 65 datasets with three predominant classes of textual explanations (highlights, free-text, and structured), organize the literature on annotating each type, identify strengths and shortcomings of existing collection methodologies, and give recommendations for collecting ExNLP datasets in the future.
翻译:可解释的NLP(ExNLP)日益注重收集人文注释,这些解释以三种方式在下游使用:作为数据增强,以提高预测性任务的业绩;作为监督,培训模型,为其预测作出解释;以及作为实地真相,评价模型产生的解释。 在这次审查中,我们确定了65个数据集,其中主要有三种文字解释(高亮、自由文本和结构化),组织关于每类说明的文献,查明现有收集方法的长处和短处,并为今后收集ExNLP数据集提出建议。