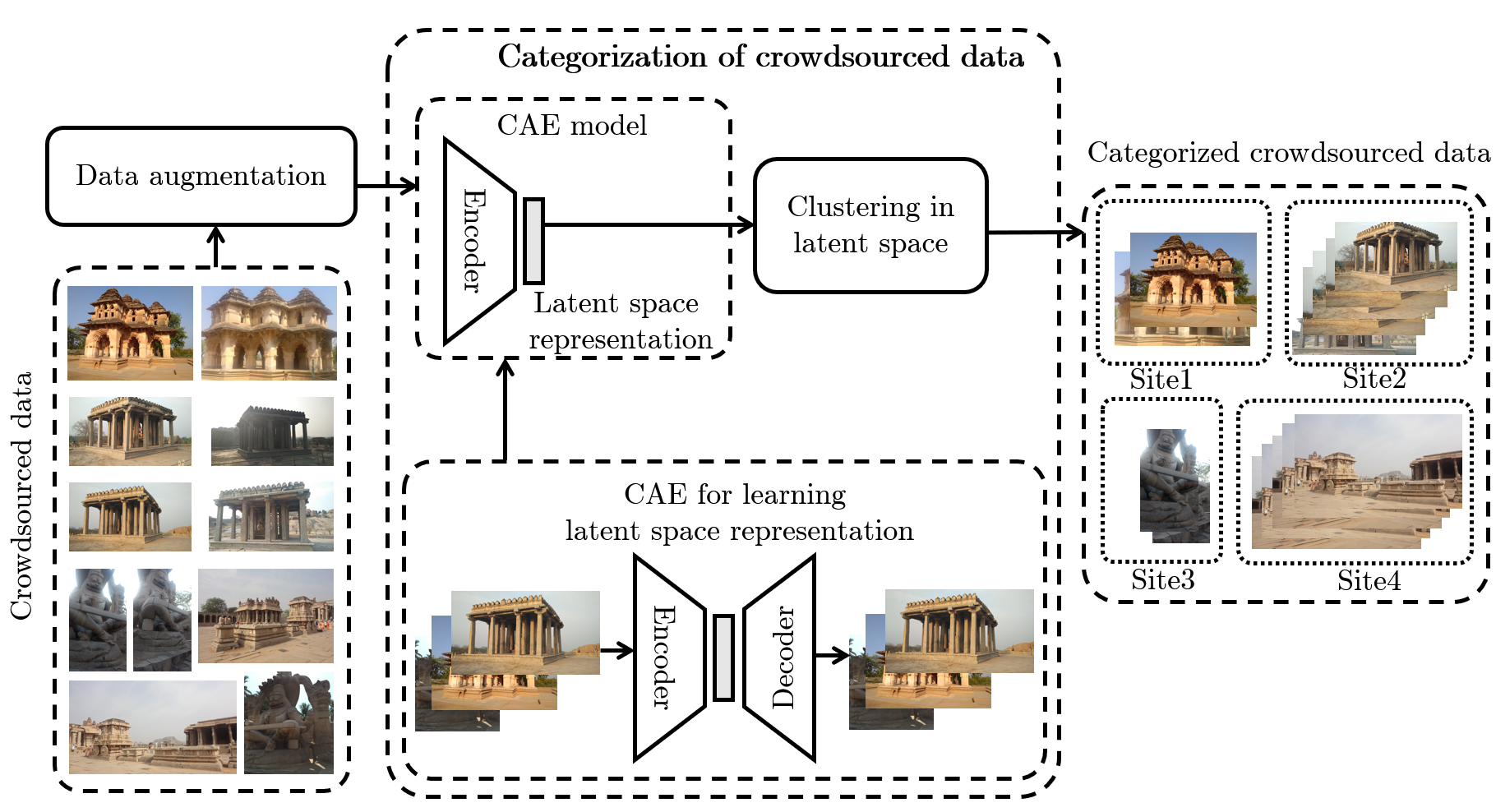
In this paper, we propose a strategy to mitigate the problem of inefficient clustering performance by introducing data augmentation as an auxiliary plug-in. Classical clustering techniques such as K-means, Gaussian mixture model and spectral clustering are central to many data-driven applications. However, recently unsupervised simultaneous feature learning and clustering using neural networks also known as Deep Embedded Clustering (DEC) has gained prominence. Pioneering works on deep feature clustering focus on defining relevant clustering loss function and choosing the right neural network for extracting features. A central problem in all these cases is data sparsity accompanied by high intra-class and low inter-class variance, which subsequently leads to poor clustering performance and erroneous candidate assignments. Towards this, we employ data augmentation techniques to improve the density of the clusters, thus improving the overall performance. We train a variant of Convolutional Autoencoder (CAE) with augmented data to construct the initial feature space as a novel model for deep clustering. We demonstrate the results of proposed strategy on crowdsourced Indian Heritage dataset. Extensive experiments show consistent improvements over existing works.
翻译:在本文中,我们提出一项战略,通过采用数据增强作为辅助插件来缓解低效集群性能问题。典型的集群技术,如K值、高斯混合模型和光谱集聚,是许多数据驱动应用的核心。然而,最近,利用神经网络(又称深嵌嵌入集群(DEC))进行不受监督的同步特征学习和集群越来越突出。关于深层特征集聚工作的先导工作侧重于界定相关集群损失功能,并选择正确的神经网络来提取特征。所有这些情况下的一个中心问题是,伴随着高等级和低等级之间差异的数据散居,随后导致高等级和低等级之间的差异,从而导致集聚积性不良和错误的候选任务。为此,我们采用数据增强技术来提高集群的密度,从而改善总体性能。我们用强化的数据来构建初始特征空间,作为深层集的新型模型。我们展示了关于众源印度遗产数据集的拟议战略的结果。广泛的实验显示,在现有工程上取得了一致的改进。