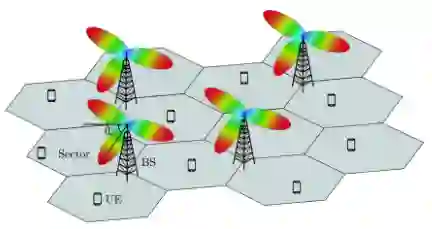
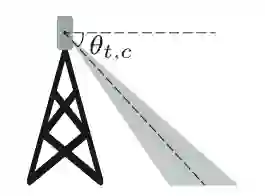
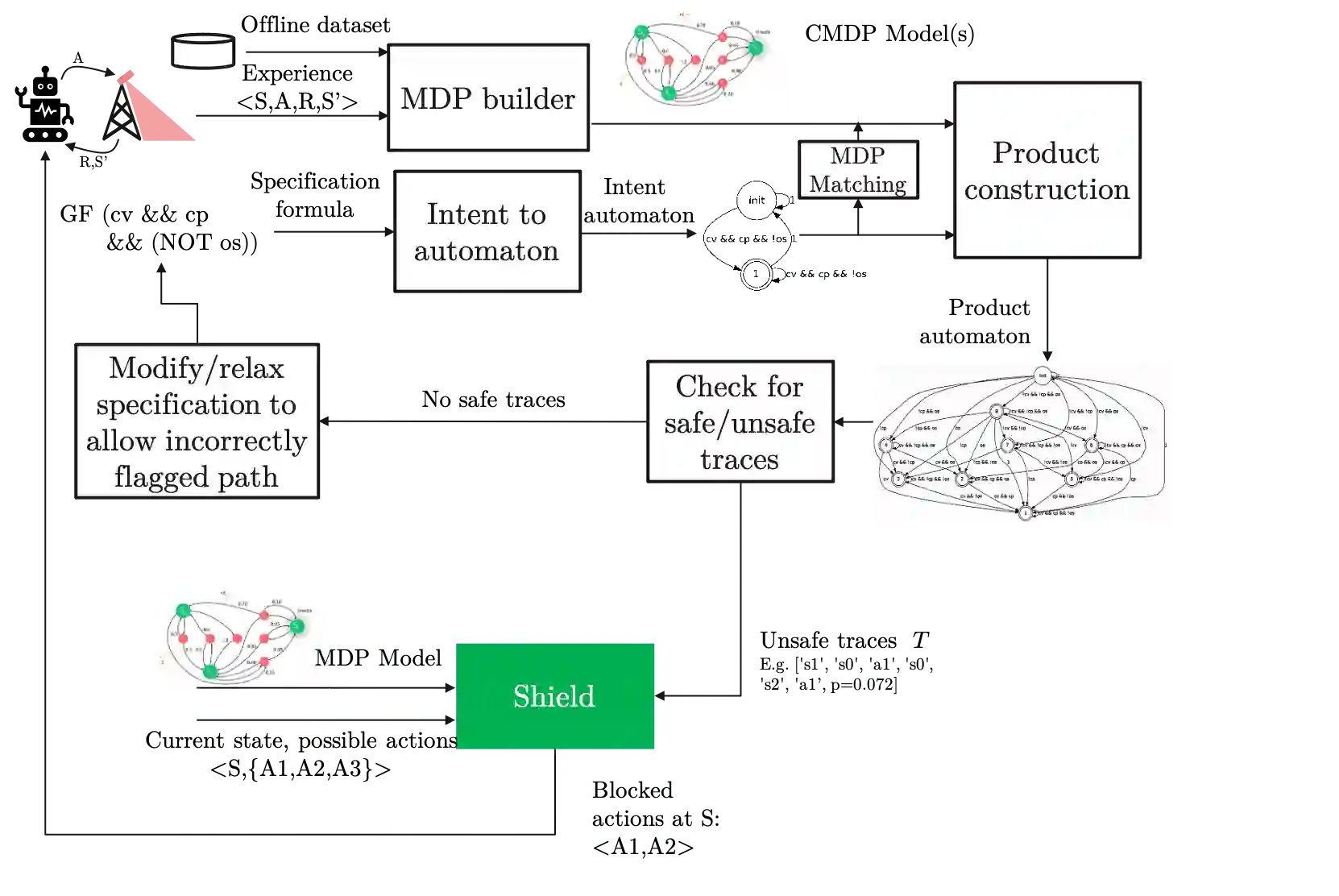
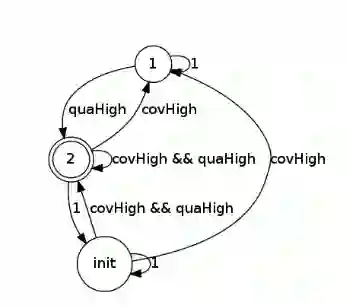
In this paper, we present a Symbolic Reinforcement Learning (SRL) based architecture for safety control of Radio Access Network (RAN) applications. In particular, we provide a purely automated procedure in which a user can specify high-level logical safety specifications for a given cellular network topology in order for the latter to execute optimal safe performance which is measured through certain Key Performance Indicators (KPIs). The network consists of a set of fixed Base Stations (BS) which are equipped with antennas, which one can control by adjusting their vertical tilt angle. The aforementioned process is called Remote Electrical Tilt (RET) optimization. Recent research has focused on performing this RET optimization by employing Reinforcement Learning (RL) strategies due to the fact that they have self-learning capabilities to adapt in uncertain environments. The term safety refers to particular constraints bounds of the network KPIs in order to guarantee that when the algorithms are deployed in a live network, the performance is maintained. In our proposed architecture the safety is ensured through model-checking techniques over combined discrete system models (automata) that are abstracted through the learning process. We introduce a user interface (UI) developed to help a user set intent specifications to the system, and inspect the difference in agent proposed actions, and those that are allowed and blocked according to the safety specification.
翻译:在本文中,我们提出了一个基于象征强化学习(SRL)的无线电接入网络应用程序安全控制架构(RAN),特别是,我们提供了一个纯粹自动化的程序,用户可以对特定蜂窝网络的地形进行高层次的逻辑安全规格,以便后者能够执行最佳的安全性能,而这种安全性能是通过某些关键业绩指标(KPIs)来衡量的。网络由一套固定基地站组成,这些基地站配备了天线,可以通过调整其垂直倾斜角度来控制。上述程序称为远程电磁优化。最近的研究侧重于通过使用强化学习(RL)战略实现可再生能源技术的优化,因为他们具备在不确定环境中适应的自学能力。“安全性能”指的是网络中的特殊限制,以保证在将算法安装在运行在运行网络中时,能保持性能。在我们提议的架构中,安全性能是通过模型检查技术,而不是通过学习过程抽象的混合离心系统模型(Automata)而得到保证。我们最近的研究侧重于通过使用强化学习学习策略来进行这种优化。我们引入了一个用户界面,这些界面,用来帮助用户根据安全性要求来检查。