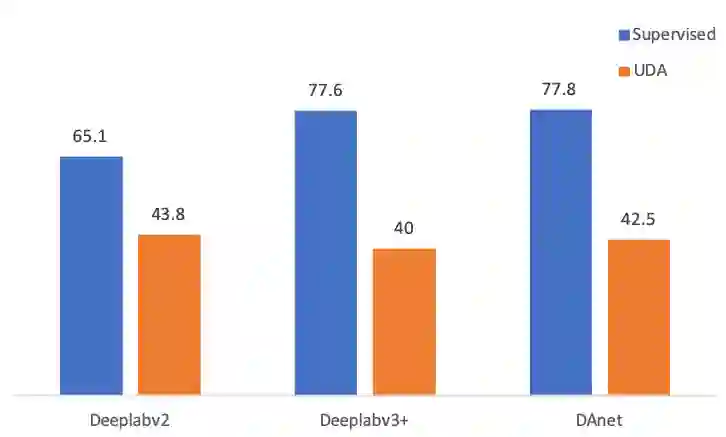
Neural network-based semantic segmentation has achieved remarkable results when large amounts of annotated data are available, that is, in the supervised case. However, such data is expensive to collect and so methods have been developed to adapt models trained on related, often synthetic data for which labels are readily available. Current adaptation approaches do not consider the dependence of the generalization/transferability of these models on network architecture. In this paper, we perform neural architecture search (NAS) to provide architecture-level perspective and analysis for domain adaptation. We identify the optimization gap that exists when searching architectures for unsupervised domain adaptation which makes this NAS problem uniquely difficult. We propose bridging this gap by using maximum mean discrepancy and regional weighted entropy to estimate the accuracy metric. Experimental results on several widely adopted benchmarks show that our proposed AutoAdapt framework indeed discovers architectures that improve the performance of a number of existing adaptation techniques.
翻译:当有大量附加说明的数据,也就是说,在受监督的情况下,基于神经网络的语义分解已经取得了显著成果,但这些数据收集费用昂贵,因此开发了各种方法,以调整经过相关、往往是合成数据培训的模型,这些模型的标签很容易获得。目前的适应方法并不考虑这些模型在网络结构上的通用/可转让性。在本文件中,我们进行神经结构搜索,为领域适应提供结构层面的视角和分析。我们找出了在寻找非受监督域适应结构时存在的优化差距,这种结构使得NAS问题特别难以解决。我们提议通过使用最大平均值差异和区域加权加权变异来缩小这一差距,以估计准确度指标。若干广泛采用的基准的实验结果表明,我们提议的AutAdapt框架确实发现了一些改进现有适应技术绩效的结构。