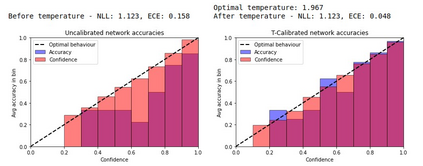
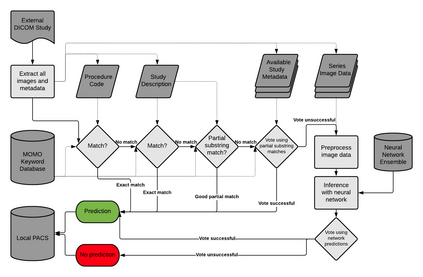
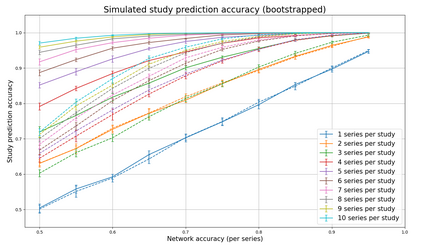
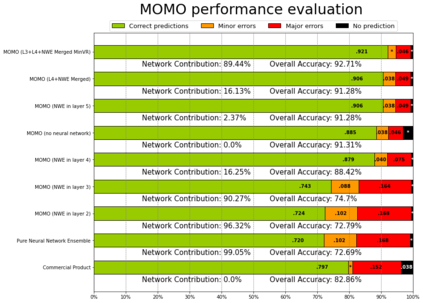
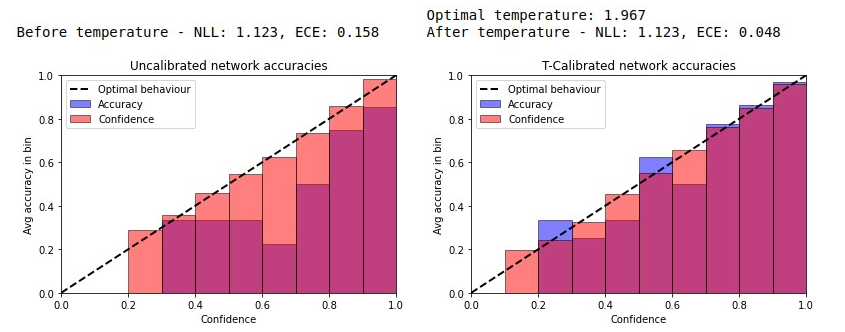
Patients regularly continue assessment or treatment in other facilities than they began them in, receiving their previous imaging studies as a CD-ROM and requiring clinical staff at the new hospital to import these studies into their local database. However, between different facilities, standards for nomenclature, contents, or even medical procedures may vary, often requiring human intervention to accurately classify the received studies in the context of the recipient hospital's standards. In this study, the authors present MOMO (MOdality Mapping and Orchestration), a deep learning-based approach to automate this mapping process utilizing metadata substring matching and a neural network ensemble, which is trained to recognize the 76 most common imaging studies across seven different modalities. A retrospective study is performed to measure the accuracy that this algorithm can provide. To this end, a set of 11,934 imaging series with existing labels was retrieved from the local hospital's PACS database to train the neural networks. A set of 843 completely anonymized external studies was hand-labeled to assess the performance of our algorithm. Additionally, an ablation study was performed to measure the performance impact of the network ensemble in the algorithm, and a comparative performance test with a commercial product was conducted. In comparison to a commercial product (96.20% predictive power, 82.86% accuracy, 1.36% minor errors), a neural network ensemble alone performs the classification task with less accuracy (99.05% predictive power, 72.69% accuracy, 10.3% minor errors). However, MOMO outperforms either by a large margin in accuracy and with increased predictive power (99.29% predictive power, 92.71% accuracy, 2.63% minor errors).
翻译:患者定期在他们最初所在的其他设施中继续进行评估或治疗,接受他们先前的成像研究,将其作为一张光盘,并要求新医院的临床工作人员将这些研究输入当地数据库。然而,在不同设施之间,命名标准、内容或甚至医疗程序可能各不相同,往往需要人干预,以便根据接受的医院的标准对收到的研究进行准确分类。在这项研究中,作者介绍了MOMO(分子绘图和交响器),这是一种基于深层次学习的方法,利用元数据子字符串匹配和神经网络合体将这一绘图进程自动化,经过培训,可以识别七种不同模式的76项最常见的成像研究。不过,为了测量这种算法能够提供的准确性,从当地医院的PACS数据库中检索了一套11 934个带有现有标签的成像系列,用于培训神经网络。一套843个完全匿名的外部研究,用手标来评估我们的算法的性能。此外,还进行了一项通货膨胀研究,以测量网络准确性影响程度的76种最常见的准确性研究。 86比值为2比值,比值为1。