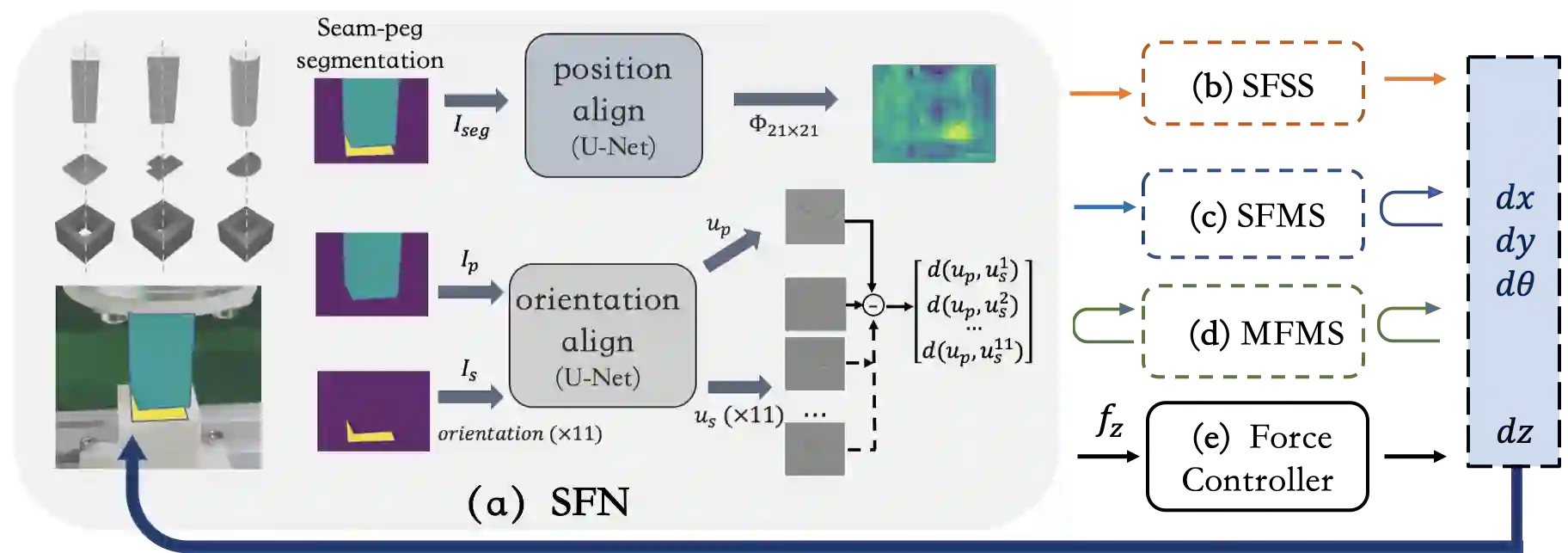
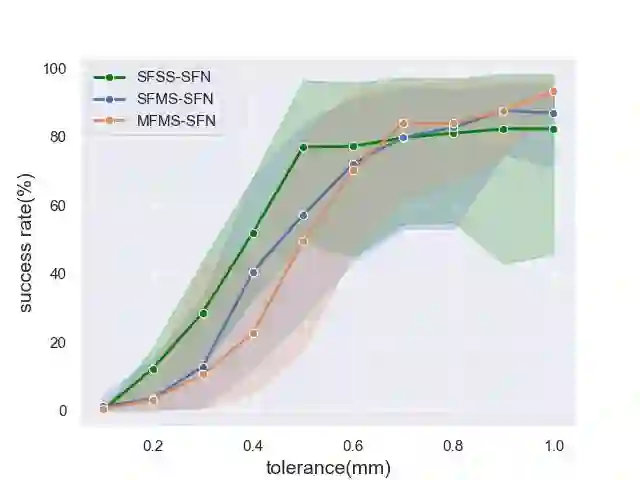
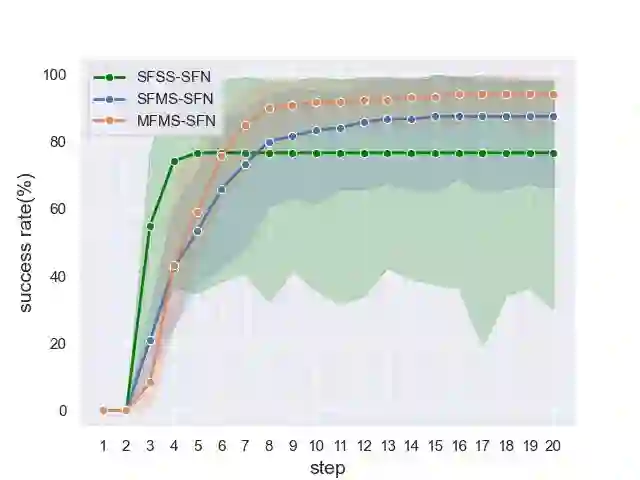
In the peg insertion task, human pays attention to the seam between the peg and the hole and tries to fill it continuously with visual feedback. By imitating the human behavior, we design architectures with position and orientation estimators based on the seam representation for pose alignment, which proves to be general to the unseen peg geometries. By putting the estimators into the closed-loop control with reinforcement learning, we further achieve a higher or comparable success rate, efficiency, and robustness compared with the baseline methods. The policy is trained totally in simulation without any manual intervention. To achieve sim-to-real, a learnable segmentation module with automatic data collecting and labeling can be easily trained to decouple the perception and the policy, which helps the model trained in simulation quickly adapt to the real world with negligible effort. Results are presented in simulation and on a physical robot. Code, videos, and supplemental material are available at https://github.com/xieliang555/SFN.git
翻译:插入 插入 任务, 人类会关注连接和洞之间的接缝, 并尝试通过视觉反馈不断填充它 。 通过模仿人类的行为, 我们设计建筑结构时, 使用以接缝代表为根据的定位和定向估计符, 这证明与隐蔽的固定地理配对是普通的。 通过用强化学习将测算器放入闭环控制中, 我们进一步实现了与基线方法相比更高或可比的成功率、 效率和稳健性。 该政策在模拟中完全接受模拟培训, 没有任何人工干预。 要实现模拟, 一个具有自动数据收集和标签的可学习分解模块, 可以很容易地接受培训, 将感知和政策分解开来, 帮助经过模拟培训的模型快速适应真实世界, 且努力微不足道。 在模拟和物理机器人上展示了结果。 代码、 视频和补充材料可在 https://github.com/xielanang555/SFNF. gitt 上查阅 。