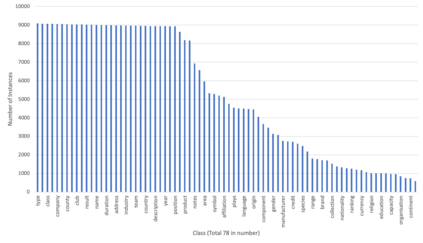
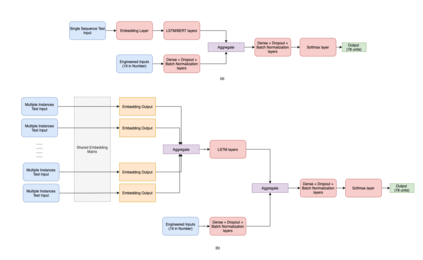
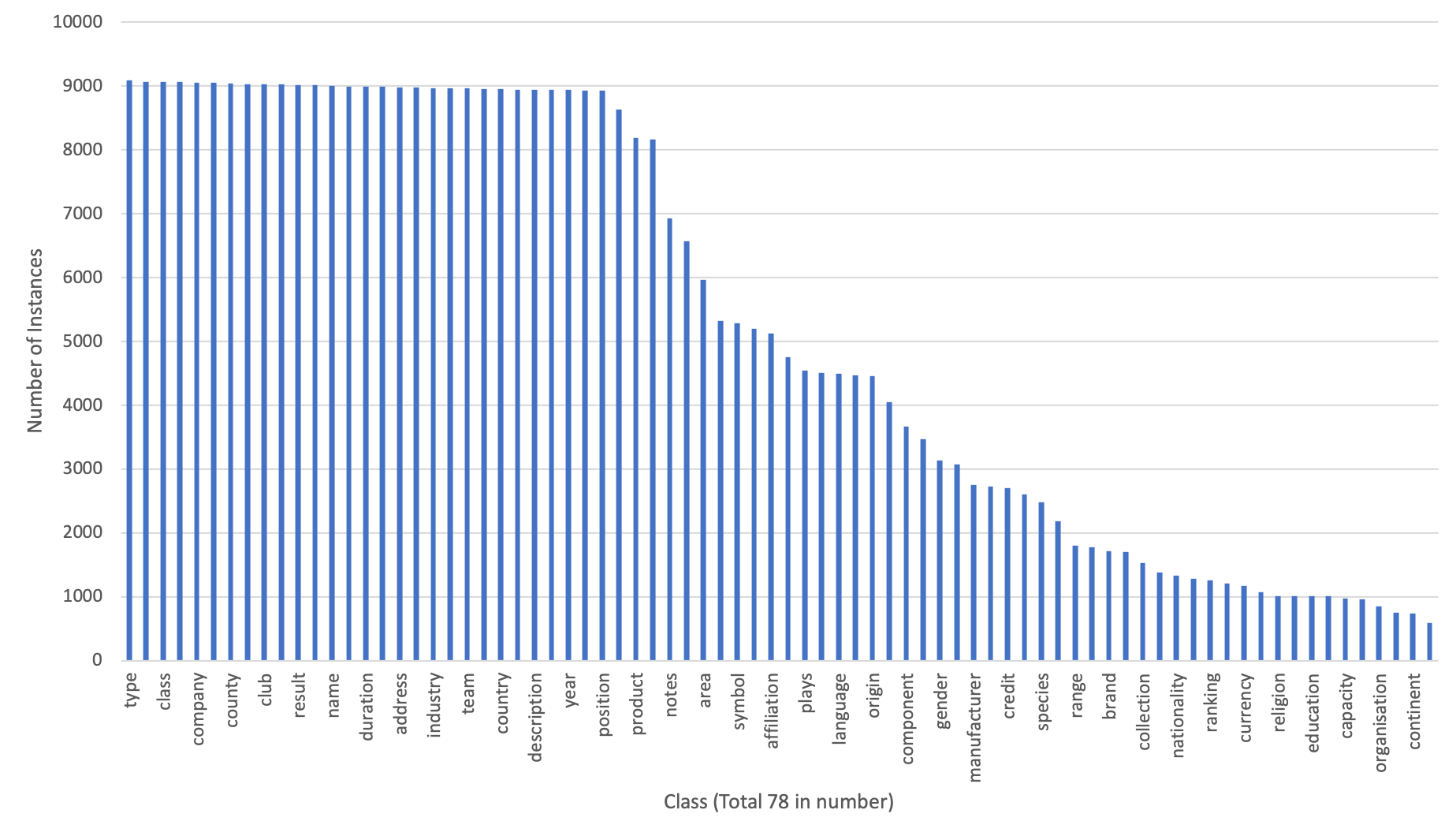
Detection of semantic data types is a very crucial task in data science for automated data cleaning, schema matching, data discovery, semantic data type normalization and sensitive data identification. Existing methods include regular expression-based or dictionary lookup-based methods that are not robust to dirty as well unseen data and are limited to a very less number of semantic data types to predict. Existing Machine Learning methods extract large number of engineered features from data and build logistic regression, random forest or feedforward neural network for this purpose. In this paper, we introduce DCoM, a collection of multi-input NLP-based deep neural networks to detect semantic data types where instead of extracting large number of features from the data, we feed the raw values of columns (or instances) to the model as texts. We train DCoM on 686,765 data columns extracted from VizNet corpus with 78 different semantic data types. DCoM outperforms other contemporary results with a quite significant margin on the same dataset.
翻译:检测语义数据类型是数据科学中自动化数据清理、系统匹配、数据发现、语义数据类型正常化和敏感数据识别方面一项非常重要的任务,现有方法包括基于表达或字典的常规查找方法,这些方法不健全,不易获取,而且不易获取,而且仅限于很少数量可以预测的语义数据类型。现有机器学习方法从数据中提取大量工程特性,并为此目的建立后勤回归、随机森林或饲料向前神经网络。在本文中,我们引入了DCoM,这是一个基于多输入NLP的深神经网络集,以探测语义数据类型,在那里,我们不是从数据中提取大量特征,而是将列(或实例)的原始值作为文本提供给模型。我们用78个不同的语义数据类型从VizNetpos中提取的686,765个数据列对DCoM进行了培训。DCoM在同一个数据集上比其他当代结果高出相当大空间。