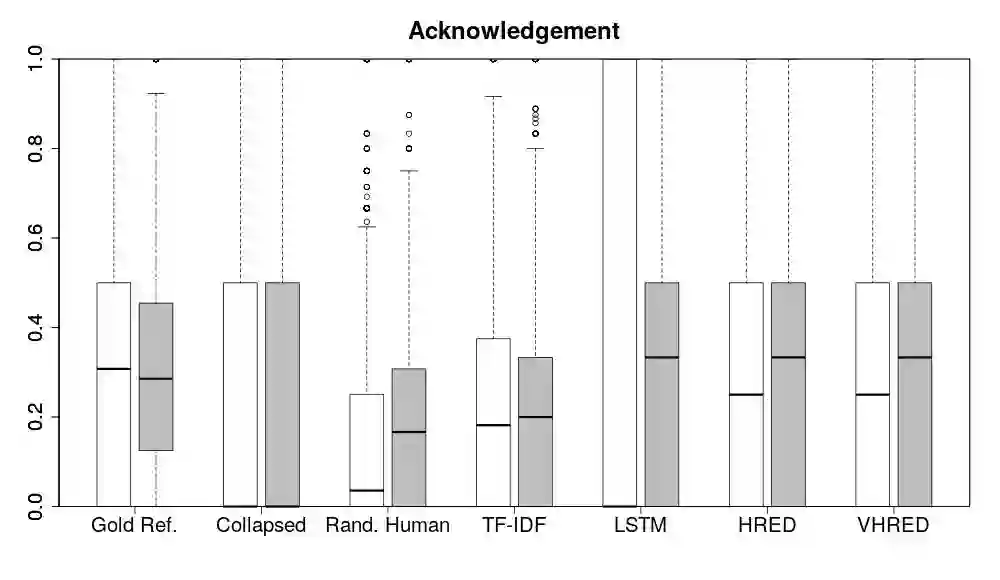
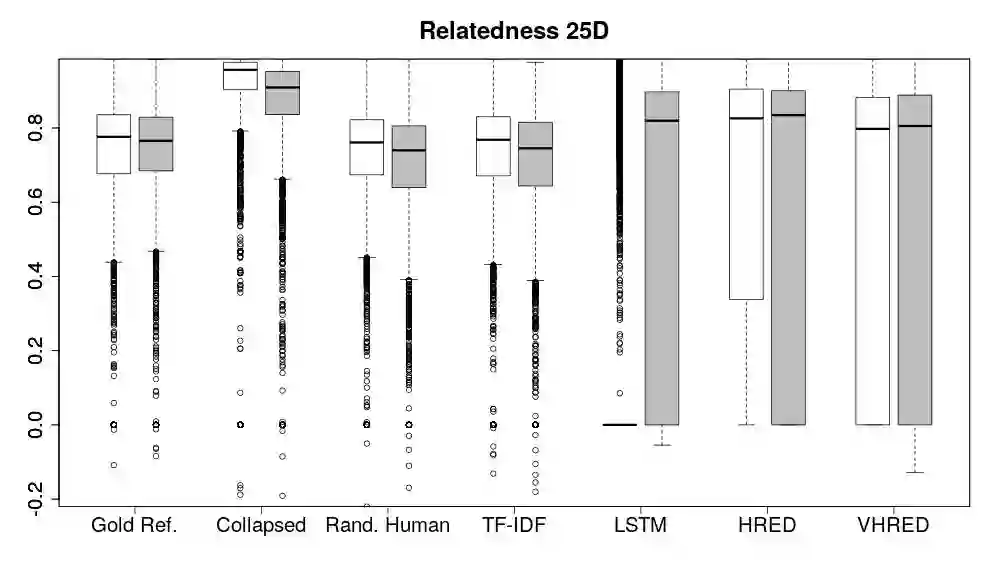
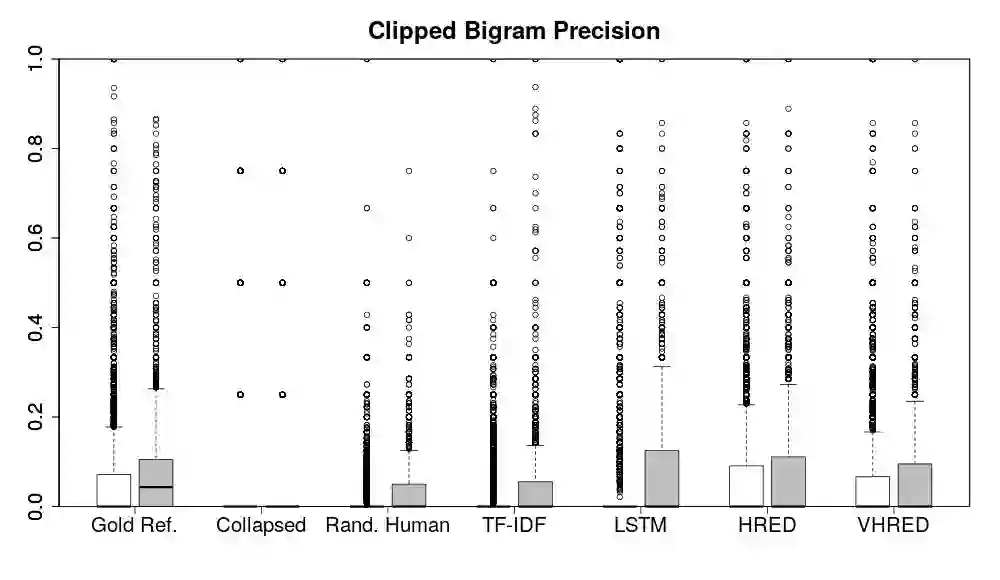
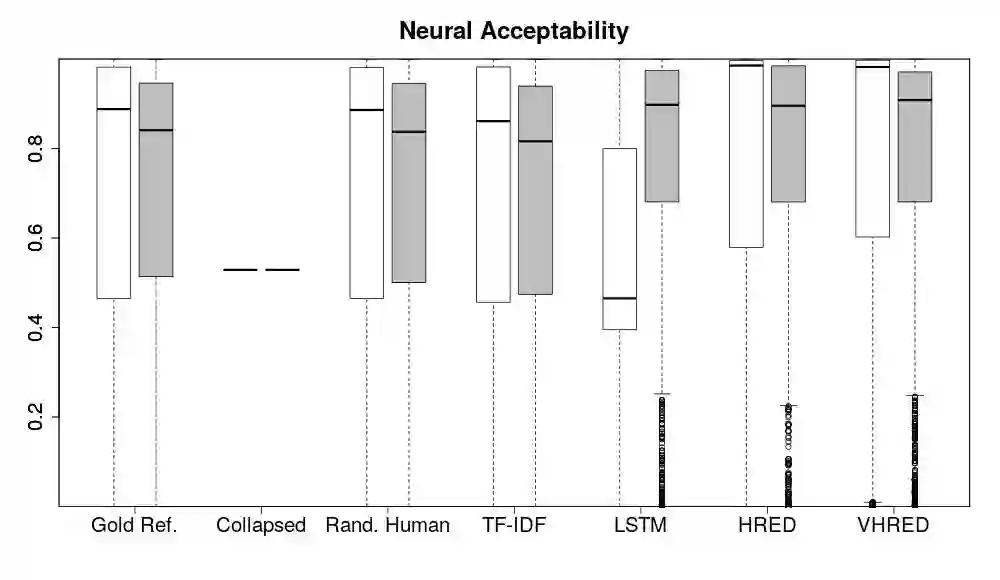
Automatically evaluating text-based, non-task-oriented dialogue systems (i.e., `chatbots') remains an open problem. Previous approaches have suffered challenges ranging from poor correlation with human judgment to poor generalization and have often required a gold standard reference for comparison or human-annotated data. Extending existing evaluation methods, we propose that a metric based on linguistic features may be able to maintain good correlation with human judgment and be interpretable, without requiring a gold-standard reference or human-annotated data. To support this proposition, we measure and analyze various linguistic features on dialogues produced by multiple dialogue models. We find that the features' behaviour is consistent with the known properties of the models tested, and is similar across domains. We also demonstrate that this approach exhibits promising properties such as zero-shot generalization to new domains on the related task of evaluating response relevance.
翻译:自动评价基于文字的、非任务导向的对话系统(即“chatbots”)仍然是一个尚未解决的问题。以前的做法一直面临各种挑战,从与人类判断的不切实际的关联到不完全的概括化,而且往往需要黄金标准参考来进行比较或提供人文附加说明的数据。扩大现有的评价方法,我们提议,基于语言特征的衡量标准可以保持与人类判断的良好关联,并且可以解释,而不需要黄金标准参考或人文附加说明的数据。为了支持这一主张,我们衡量和分析多种对话模式产生的对话的各种语言特征。我们发现,这些特征的行为与所测试的模式的已知特性是一致的,而且在不同领域类似。我们还表明,这一方法在评估响应相关性的相关任务上,在新领域展示了如零点概括化等有希望的特性。