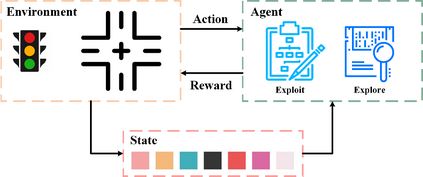
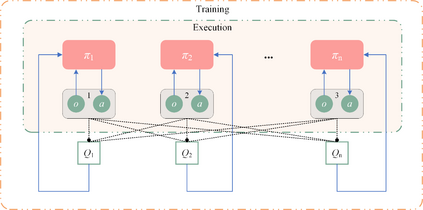
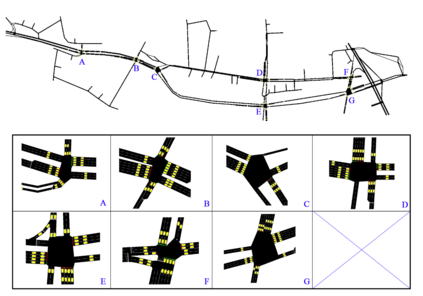
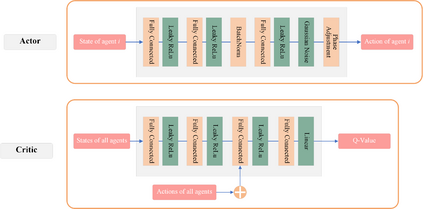
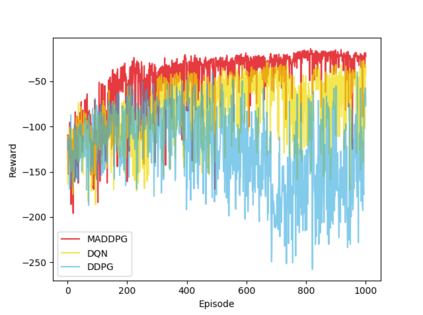
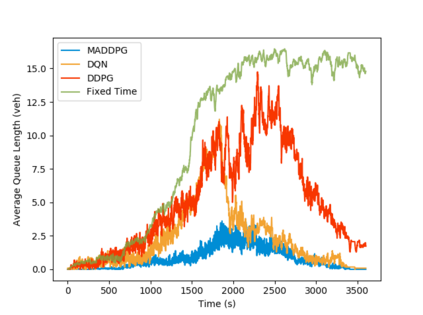
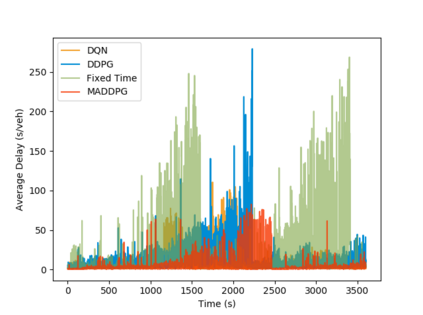
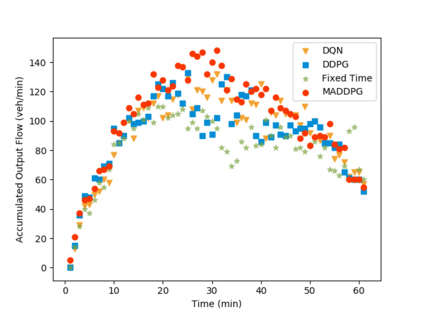
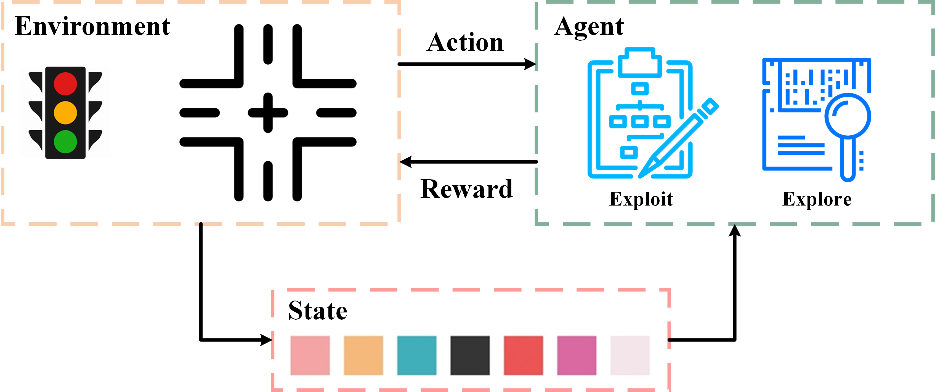
Inefficient traffic signal control methods may cause numerous problems, such as traffic congestion and waste of energy. Reinforcement learning (RL) is a trending data-driven approach for adaptive traffic signal control in complex urban traffic networks. Although the development of deep neural networks (DNN) further enhances its learning capability, there are still some challenges in applying deep RLs to transportation networks with multiple signalized intersections, including non-stationarity environment, exploration-exploitation dilemma, multi-agent training schemes, continuous action spaces, etc. In order to address these issues, this paper first proposes a multi-agent deep deterministic policy gradient (MADDPG) method by extending the actor-critic policy gradient algorithms. MADDPG has a centralized learning and decentralized execution paradigm in which critics use additional information to streamline the training process, while actors act on their own local observations. The model is evaluated via simulation on the Simulation of Urban MObility (SUMO) platform. Model comparison results show the efficiency of the proposed algorithm in controlling traffic lights.
翻译:交通信号控制方法效率不高可能会造成许多问题,例如交通堵塞和能源浪费。强化学习(RL)是一种趋势式的数据驱动方法,用于复杂城市交通网络的适应性交通信号控制。虽然深神经网络的发展进一步加强了其学习能力,但在将深RL应用于具有多种信号交叉点的运输网络方面仍然存在一些挑战,包括非常态环境、探索-开发困境、多试剂培训计划、连续行动空间等。为了解决这些问题,本文件首先建议采用多试剂的深度确定性政策梯度(MADDPG)方法,扩大行为者-批评政策梯度算法。MADDPG有一个集中的学习和分散执行模式,批评者在其中利用额外信息精简培训进程,而行为者则根据自己的当地观察行动。模型通过模拟城市移动平台(SUMO)来评估。模型比较结果显示拟议的算法在控制交通灯方面的效率。