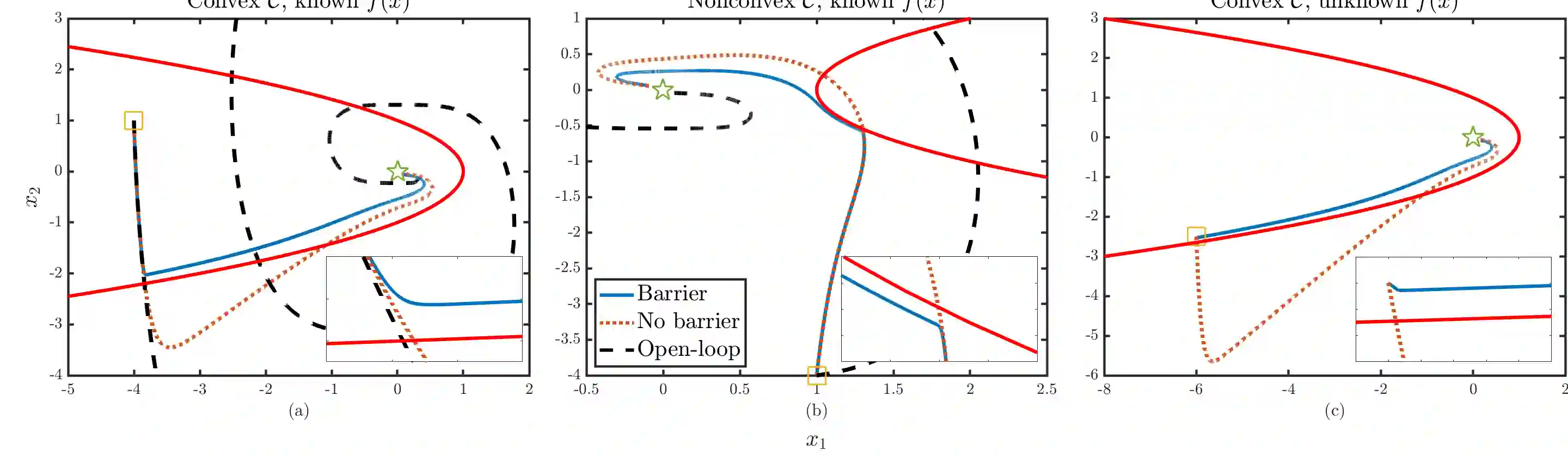
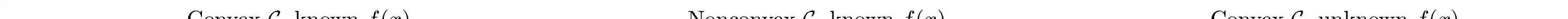This paper studies the problem of developing an approximate dynamic programming (ADP) framework for learning online the value function of an infinite-horizon optimal problem while obeying safety constraints expressed as control barrier functions (CBFs). Our approach is facilitated by the development of a novel class of CBFs, termed Lyapunov-like CBFs (LCBFs), that retain the beneficial properties of CBFs for developing minimally-invasive safe control policies while also possessing desirable Lyapunov-like qualities such as positive semi-definiteness. We show how these LCBFs can be used to augment a learning-based control policy so as to guarantee safety and then leverage this approach to develop a safe exploration framework in a model-based reinforcement learning setting. We demonstrate that our developed approach can handle more general safety constraints than state-of-the-art safe ADP methods through a variety of numerical examples.
翻译:本文研究开发一个大致动态方案规划框架(ADP),在网上学习一个无限之平的最佳问题的价值功能,同时遵守作为控制屏障功能(CBFs)所表达的安全限制(CBFs)的问题。我们的方法通过开发一个新型的CBFs(称为Lyapunov-类似CBFs(LCDFs))得到推动,这些CBFs保留了CBFs的有益特性,用于制定最低侵入性安全控制政策,同时拥有像Lyapunov这样的像Lyapunov一样的品质,如积极的半确定性。我们展示了如何利用这些LCBFs来加强基于学习的控制政策,以保障安全,然后在基于模型的强化学习环境中利用这一方法制定安全探索框架。我们通过各种数字实例表明,我们制定的方法可以处理比最先进的安全ADP方法更一般性的安全限制。