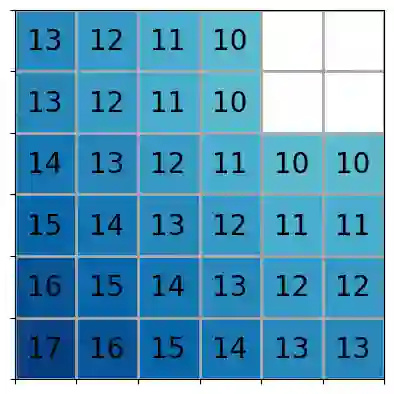
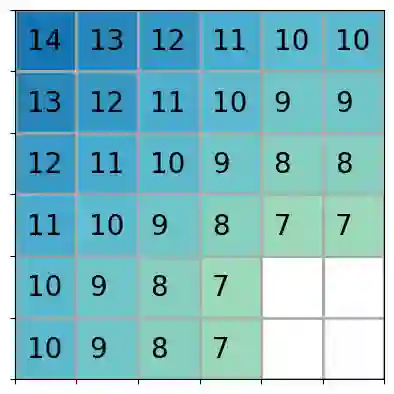
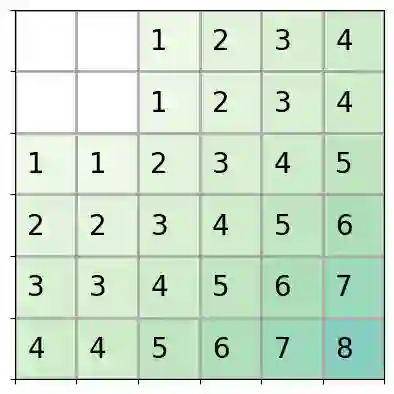
Reinforcement learning (RL) is a popular approach for robotic path planning in uncertain environments. However, the control policies trained for an RL agent crucially depend on user-defined, state-based reward functions. Poorly designed rewards can lead to policies that do get maximal rewards but fail to satisfy desired task objectives or are unsafe. There are several examples of the use of formal languages such as temporal logics and automata to specify high-level task specifications for robots (in lieu of Markovian rewards). Recent efforts have focused on inferring state-based rewards from formal specifications; here, the goal is to provide (probabilistic) guarantees that the policy learned using RL (with the inferred rewards) satisfies the high-level formal specification. A key drawback of several of these techniques is that the rewards that they infer are sparse: the agent receives positive rewards only upon completion of the task and no rewards otherwise. This naturally leads to poor convergence properties and high variance during RL. In this work, we propose using formal specifications in the form of symbolic automata: these serve as a generalization of both bounded-time temporal logic-based specifications as well as automata. Furthermore, our use of symbolic automata allows us to define non-sparse potential-based rewards which empirically shape the reward surface, leading to better convergence during RL. We also show that our potential-based rewarding strategy still allows us to obtain the policy that maximizes the satisfaction of the given specification.
翻译:强化学习(RL)是在不确定的环境中进行机器人路径规划的流行方法。然而,为RL代理商培训的控制政策主要取决于用户定义的、以国家为基础的奖赏功能。设计不当的奖励可能导致政策得到最大回报,但未能达到预期任务目标或不安全。有一些例子说明使用正式语言,如时间逻辑和自动地图来指定机器人的高层次任务规格(代替Markovian奖赏)。最近的努力侧重于从正式的规格中推断基于国家的奖赏;在此,目标是提供(概率)保证使用RL(以及推断的奖赏)所学的政策符合高级别的正式规格。设计不当的奖励可能导致一些技术被忽略:代理人只是在完成任务后才获得积极奖赏,而没有获得其他奖赏。这自然导致机器人在基于RL(RL)的高级任务规格(而不是Markovian奖赏)期间的特性不高差异很大。我们提议使用基于象征性的自动自动化的规格:这些是既具有约束性的又具有概率的、又具有推导力的、又能使我们在不具有最精确的精确的精确的逻辑价值时,从而能够将我们获得以自动的奖赏作为Agalalalalal的奖赏。