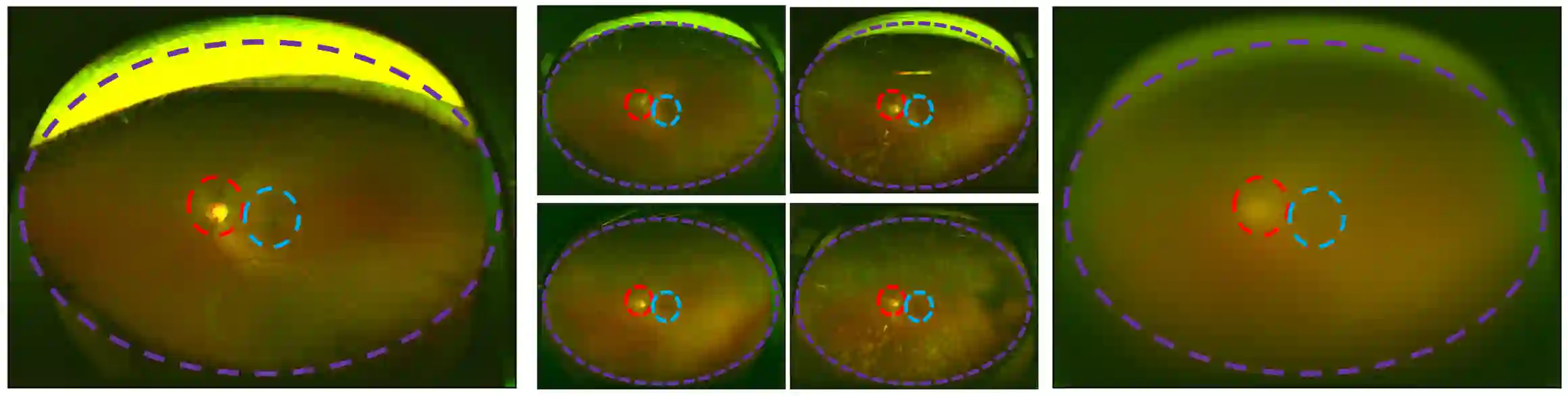
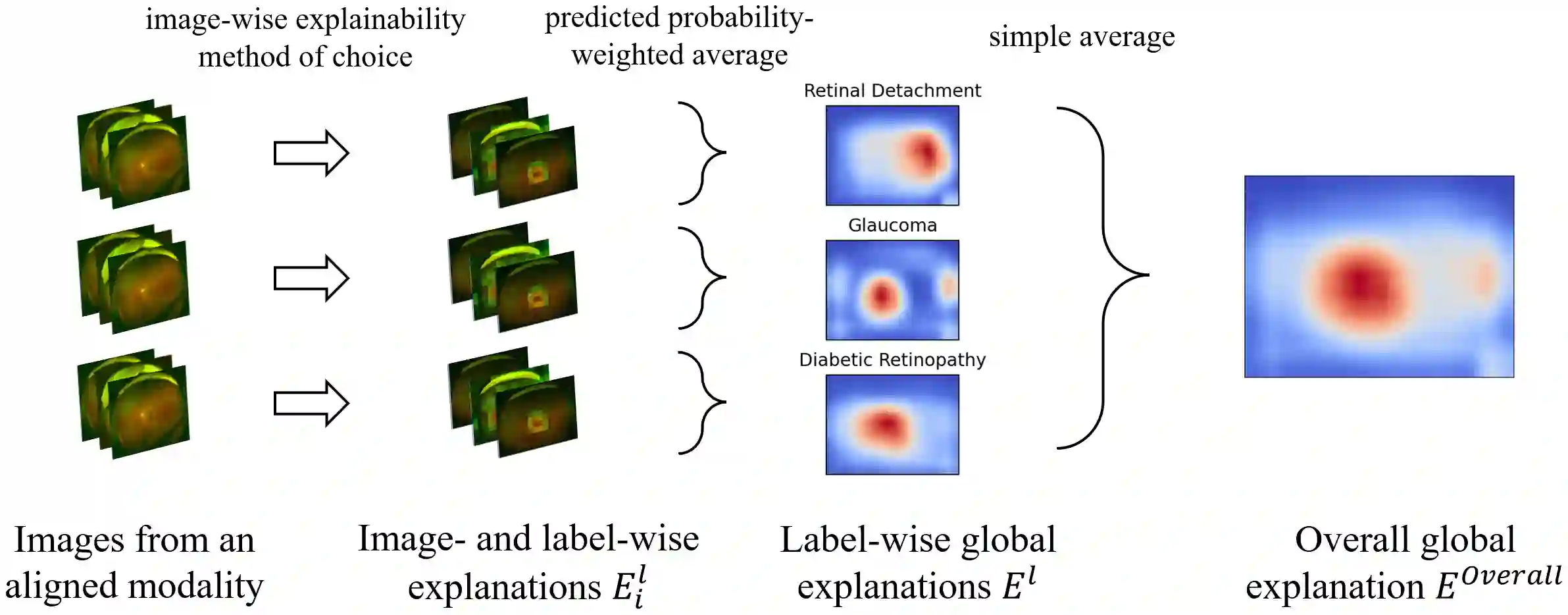
Deep learning (DL) models are very effective on many computer vision problems and increasingly used in critical applications. They are also inherently black box. A number of methods exist to generate image-wise explanations that allow practitioners to understand and verify model predictions for a given image. Beyond that, it would be desirable to validate that a DL model \textit{generally} works in a sensible way, i.e. consistent with domain knowledge and not relying on undesirable data artefacts. For this purpose, the model needs to be explained globally. In this work, we focus on image modalities that are naturally aligned such that each pixel position represents a similar relative position on the imaged object, as is common in medical imaging. We propose the pixel-wise aggregation of image-wise explanations as a simple method to obtain label-wise and overall global explanations. These can then be used for model validation, knowledge discovery, and as an efficient way to communicate qualitative conclusions drawn from inspecting image-wise explanations. We further propose Progressive Erasing Plus Progressive Restoration (PEPPR) as a method to quantitatively validate that these global explanations are faithful to how the model makes its predictions. We then apply these methods to ultra-widefield retinal images, a naturally aligned modality. We find that the global explanations are consistent with domain knowledge and faithfully reflect the model's workings.
翻译:深度学习模式( DL) 在许多计算机视觉问题上非常有效,并且越来越多地用于关键应用。 它们本身也是黑盒。 有一些方法可以产生图像化的解释, 让执行人员能够理解和验证特定图像的模型预测。 此外, 最好验证一个 DL 模型 \ textit{ 一般来说是可行的, 即符合域知识, 而不是依赖不受欢迎的数据手工艺。 为此, 模型需要在全球解释。 在这项工作中, 我们注重自然匹配的图像模式, 使每个像素位置在图像对象上代表相似的相对位置, 如医学成像中常见的。 我们提议以像素化的图像化解释组合为简单方法, 以获得标签化和总体的全球解释。 然后, 这些方法可用于模型验证、 知识发现, 并作为一种有效的方法, 传达从图像学解释中得出的质量结论。 我们进一步提议, 渐进的 Erasing + 进步恢复 (PEPR ), 作为定量验证这些全球解释是否忠实于模型如何进行预测的相对一致的模型的方法, 我们随后将这些方法应用到一个精确的模型。