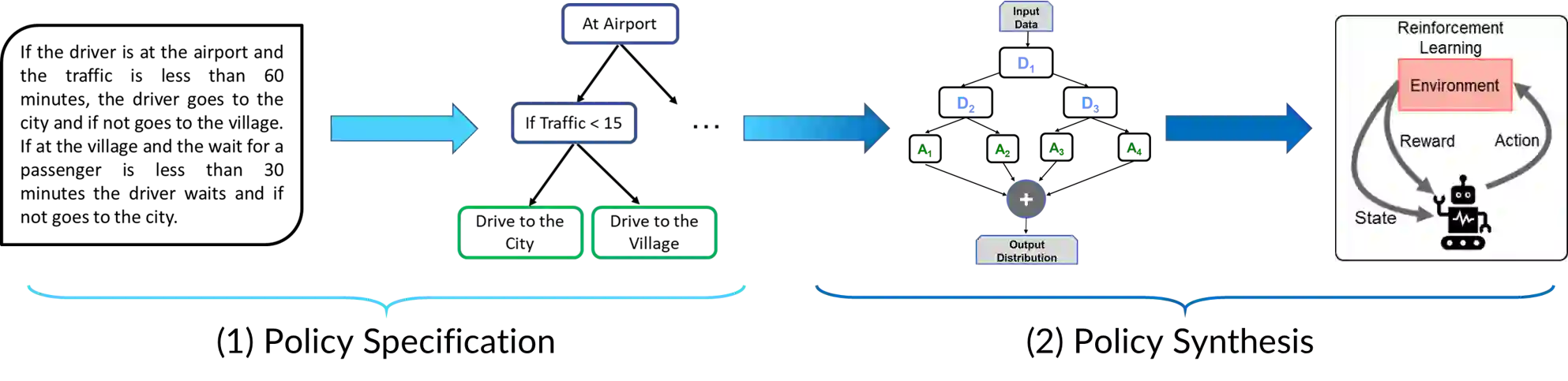
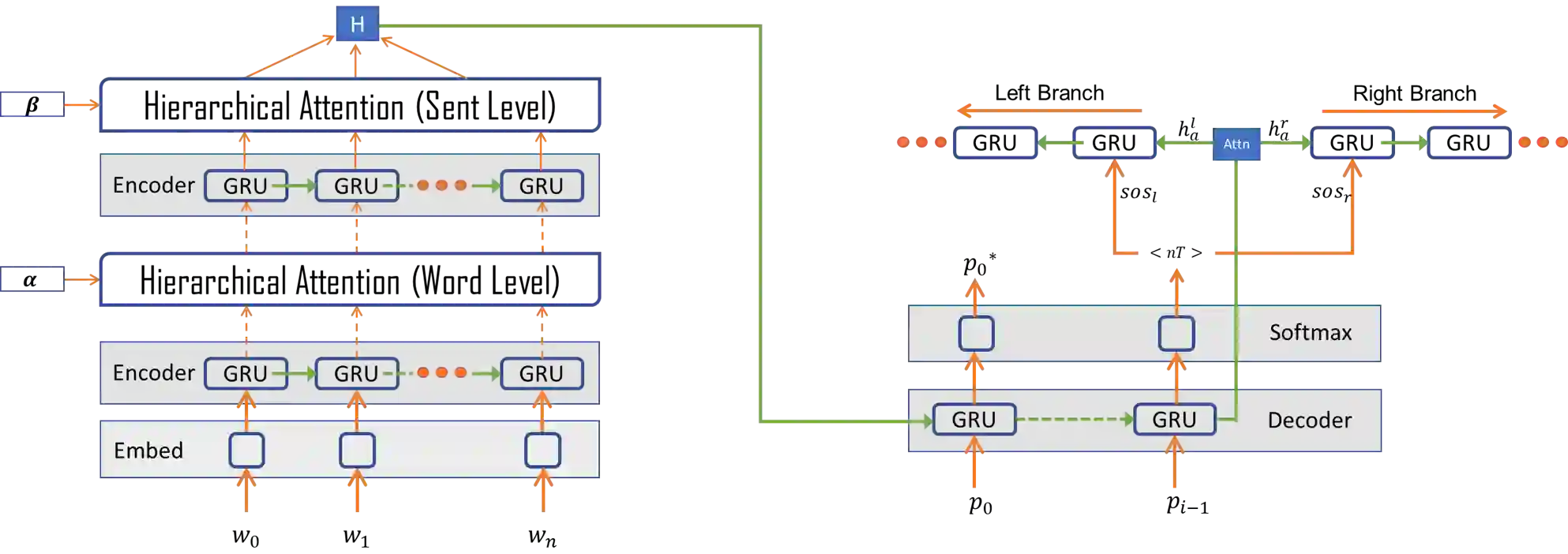
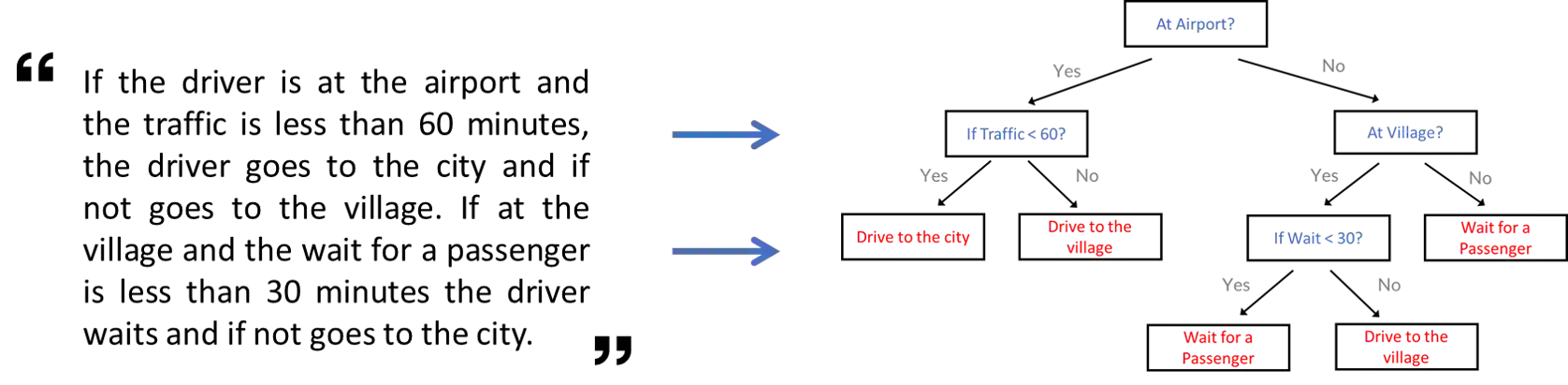
Policy specification is a process by which a human can initialize a robot's behaviour and, in turn, warm-start policy optimization via Reinforcement Learning (RL). While policy specification/design is inherently a collaborative process, modern methods based on Learning from Demonstration or Deep RL lack the model interpretability and accessibility to be classified as such. Current state-of-the-art methods for policy specification rely on black-box models, which are an insufficient means of collaboration for non-expert users: These models provide no means of inspecting policies learnt by the agent and are not focused on creating a usable modality for teaching robot behaviour. In this paper, we propose a novel machine learning framework that enables humans to 1) specify, through natural language, interpretable policies in the form of easy-to-understand decision trees, 2) leverage these policies to warm-start reinforcement learning and 3) outperform baselines that lack our natural language initialization mechanism. We train our approach by collecting a first-of-its-kind corpus mapping free-form natural language policy descriptions to decision tree-based policies. We show that our novel framework translates natural language to decision trees with a 96% and 97% accuracy on a held-out corpus across two domains, respectively. Finally, we validate that policies initialized with natural language commands are able to significantly outperform relevant baselines (p < 0.001) that do not benefit from our natural language-based warm-start technique.
翻译:政策规格是一个过程,人类可以借此启动机器人的行为,而反过来又可以通过强化学习(RL)来启动热启动政策优化。虽然政策规格/设计本质上是一个协作过程,但基于演示或深RL学习的现代方法缺乏模型解释性和可被归类性。目前最先进的政策规格方法依赖于黑盒模式,而黑盒模式对非专家用户来说是不充分的协作手段:这些模式没有提供检验代理人所学政策的手段,也没有侧重于创建可用于教授机器人行为的模式。在本文中,我们提议了一个新颖的机器学习框架,使人类能够1)通过自然语言,以易于理解的决定树的形式,具体说明可解释的政策,2)利用这些政策来暖启动强化学习,3)超越缺乏我们自然语言初始启动机制的基线。我们通过收集以原始材料为主的绘制基于自由格式的自然语言政策描述来培训我们的方法。我们展示了我们的新框架将自然语言翻译为决定树,其初始语言为96 % 和初始语言为97 % 的自然定位系统将分别用于自然基准系统,最终的精确度将我们掌握的自然定位系统,从而在初始和初始的自然定位上,最终的精确度将两个区域进行。