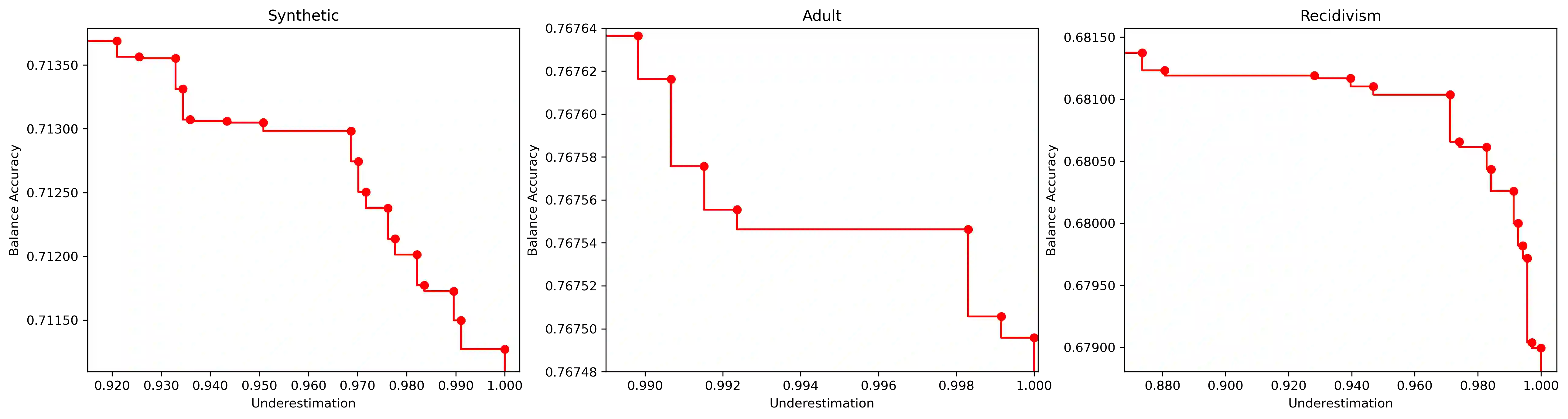
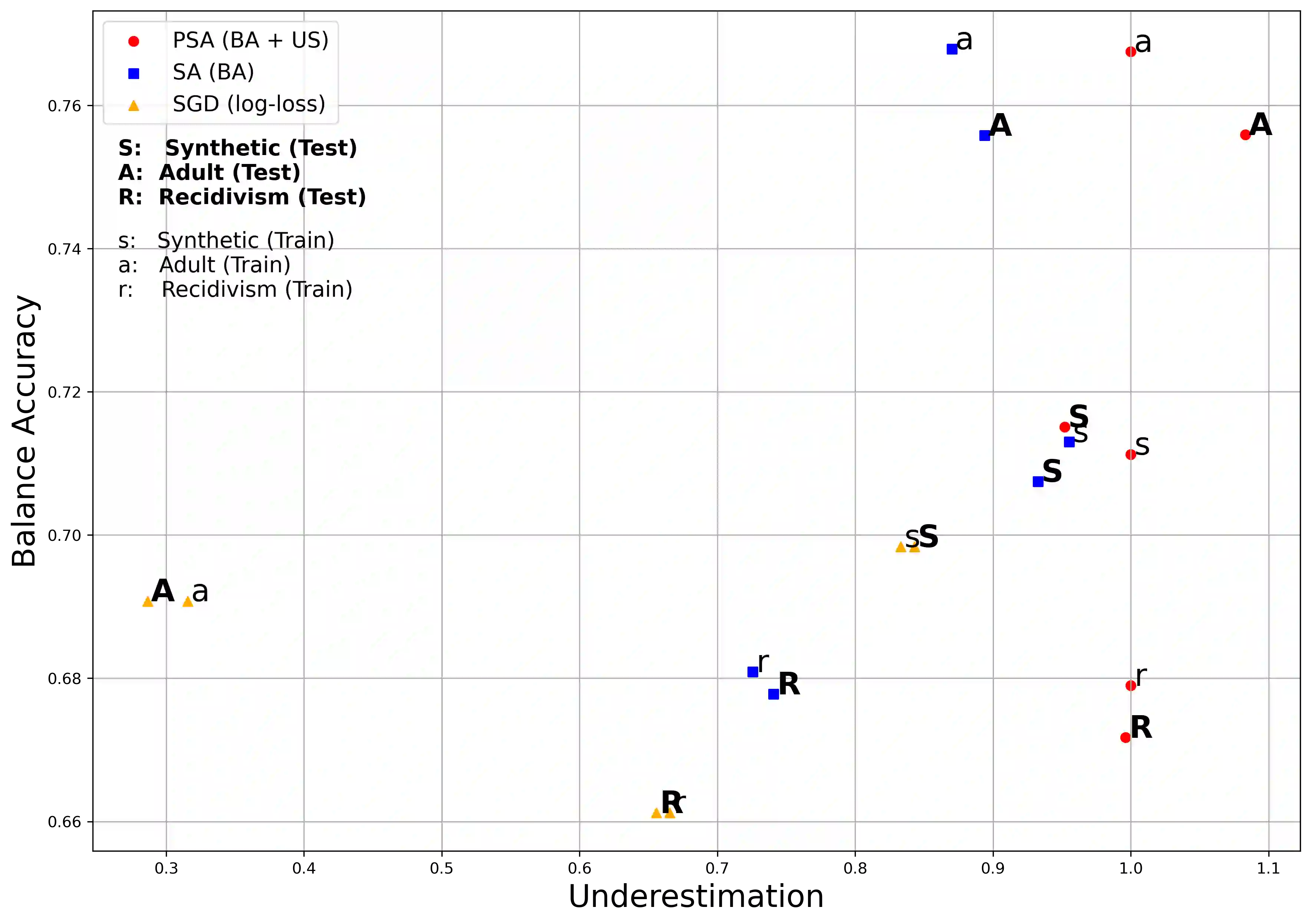
Algorithmic Bias can be due to bias in the training data or issues with the algorithm itself. These algorithmic issues typically relate to problems with model capacity and regularisation. This underestimation bias may arise because the model has been optimised for good generalisation accuracy without any explicit consideration of bias or fairness. In a sense, we should not be surprised that a model might be biased when it hasn't been "asked" not to be. In this paper, we consider including bias (underestimation) as an additional criterion in model training. We present a multi-objective optimisation strategy using Pareto Simulated Annealing that optimise for both balanced accuracy and underestimation. We demonstrate the effectiveness of this strategy on one synthetic and two real-world datasets.
翻译:分析比亚斯的偏差可能是由于培训数据中的偏差或算法本身的问题。 这些算法问题通常与模型容量和正规化的问题有关。 这种低估偏差可能出现,因为模型在没有明确考虑偏差或公平性的情况下被优化为一般化的准确性。 从某种意义上讲,当模型没有被“禁止”时,我们并不感到惊讶。 在本文中,我们认为将偏差(低估)列为模型培训的附加标准。 我们提出了一个多目标优化战略,使用 Pareto 模拟安妮纳林(Annamaling) 来优化平衡准确性和低估性。 我们用一个合成和两个真实世界数据集来展示这一战略的有效性。