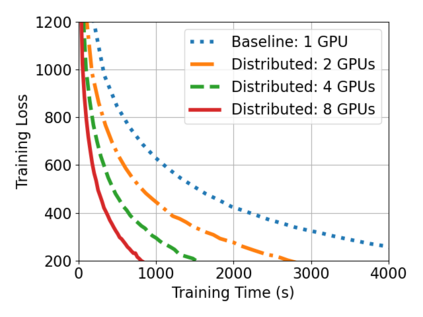
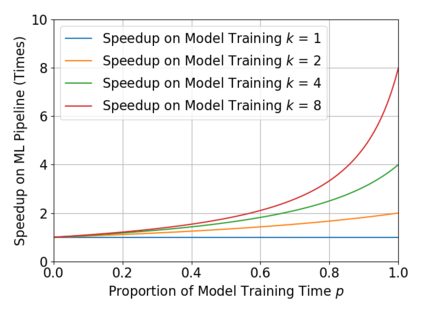
With the ever-increasing adoption of machine learning for data analytics, maintaining a machine learning pipeline is becoming more complex as both the datasets and trained models evolve with time. In a collaborative environment, the changes and updates due to pipeline evolution often cause cumbersome coordination and maintenance work, raising the costs and making it hard to use. Existing solutions, unfortunately, do not address the version evolution problem, especially in a collaborative environment where non-linear version control semantics are necessary to isolate operations made by different user roles. The lack of version control semantics also incurs unnecessary storage consumption and lowers efficiency due to data duplication and repeated data pre-processing, which are avoidable. In this paper, we identify two main challenges that arise during the deployment of machine learning pipelines, and address them with the design of versioning for an end-to-end analytics system MLCask. The system supports multiple user roles with the ability to perform Git-like branching and merging operations in the context of the machine learning pipelines. We define and accelerate the metric-driven merge operation by pruning the pipeline search tree using reusable history records and pipeline compatibility information. Further, we design and implement the prioritized pipeline search, which gives preference to the pipelines that probably yield better performance. The effectiveness of MLCask is evaluated through an extensive study over several real-world deployment cases. The performance evaluation shows that the proposed merge operation is up to 7.8x faster and saves up to 11.9x storage space than the baseline method that does not utilize history records.
翻译:随着数据分析日益采用机器学习方法,随着数据集和经过培训的模型的不断演变,保持机器学习管道变得越来越复杂,随着数据集和经过培训的模型的不断演变,维护机器学习管道变得日益复杂。在合作环境中,由于管道演变而产生的变化和更新往往导致协调和维护工作繁琐、成本增加和难以使用。不幸的是,现有解决方案无法解决版本演变问题,特别是在非线性版本控制语义需要将不同用户角色的操作分离开来的协作环境中。版本控制语义的缺乏也造成不必要的存储消耗和效率降低,因为数据重复和重复的预处理是可以避免的。在本文中,我们找出了在安装机器学习管道过程中出现的两大挑战,这些变化和更新往往导致协调和维护,并解决了这些挑战,为最终至最终分析系统设计了版本。系统支持多种用户的作用,在机器学习管道中能够进行类似分支化和合并操作。我们定义并加快了标准化驱动的合并操作,方法是利用可再利用的基线搜索树和重复的预处理,这是可以避免的。 在本文件中,我们找出了在安装可更新的历史记录和编程过程中的进度记录时,可以进行更精确的运行。