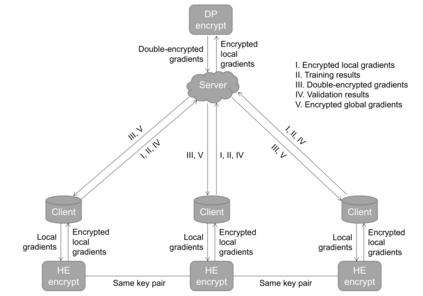
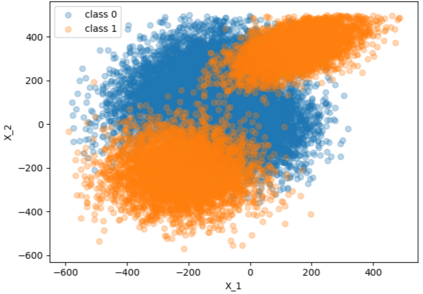
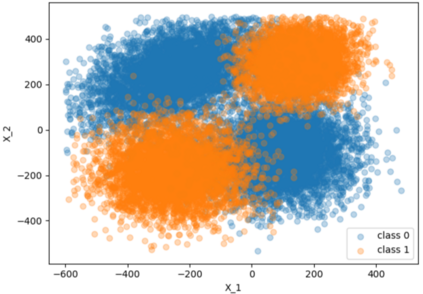
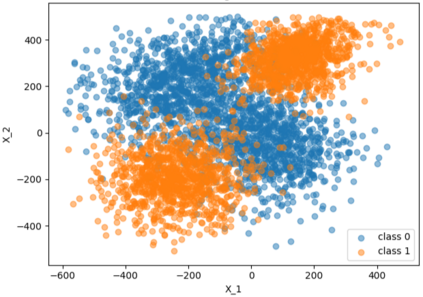
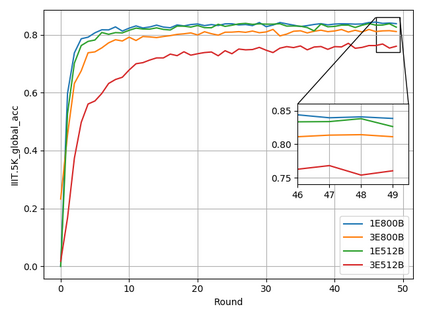
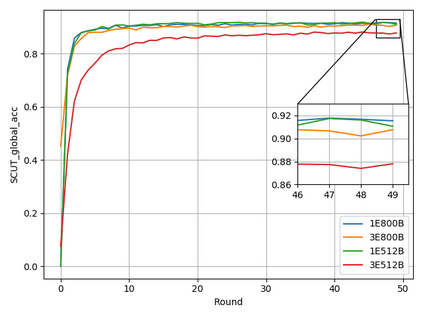
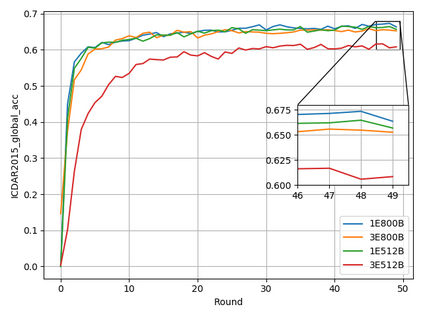
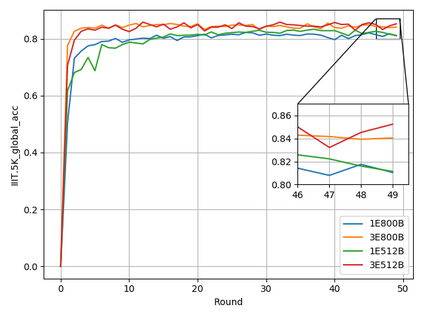
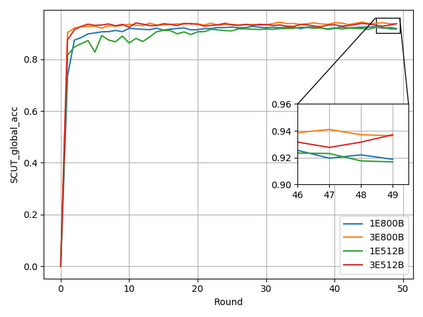
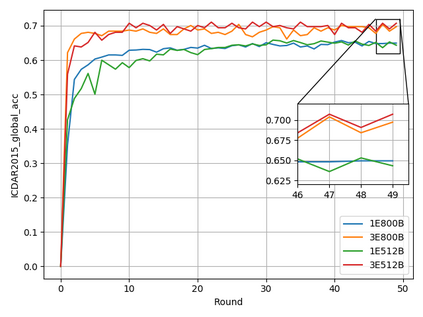
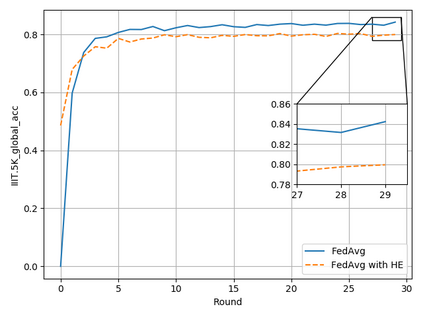
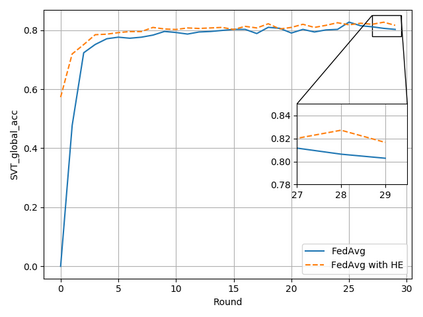
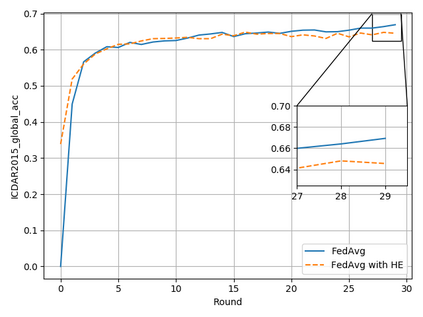
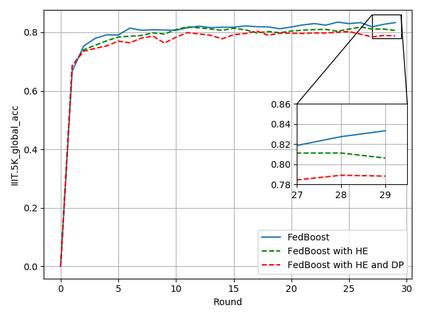
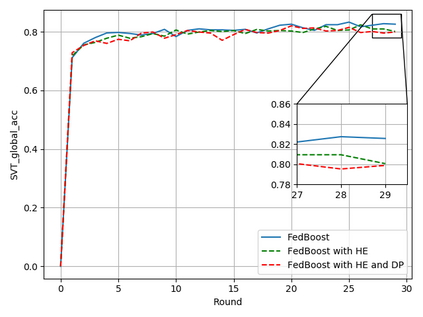
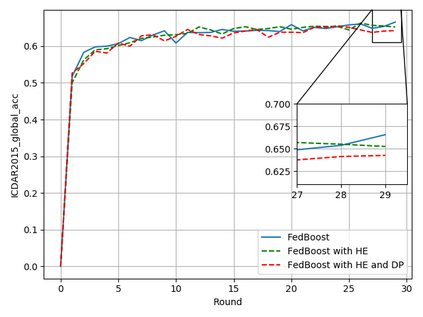
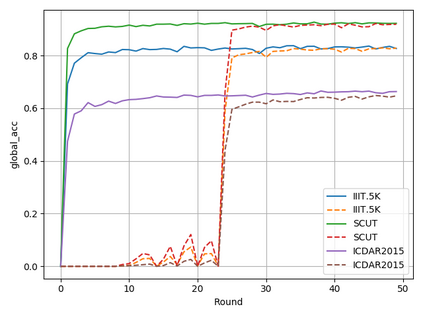
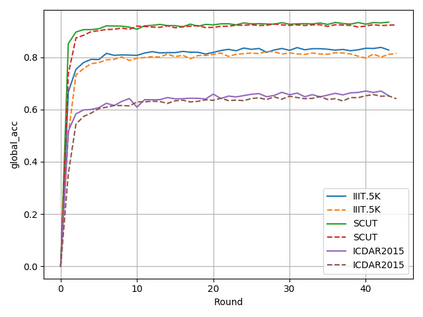
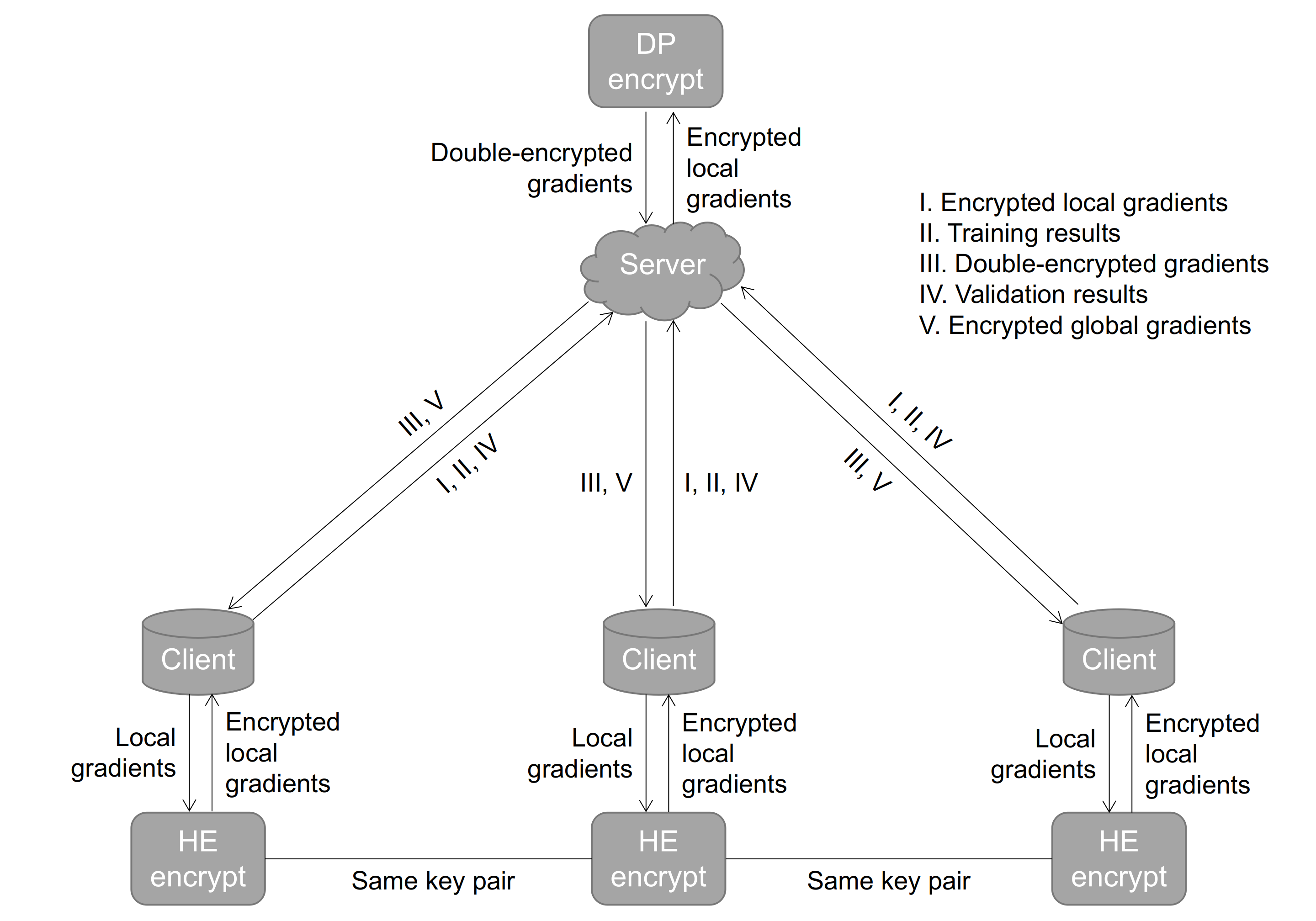
Typical machine learning approaches require centralized data for model training, which may not be possible where restrictions on data sharing are in place due to, for instance, privacy and gradient protection. The recently proposed Federated Learning (FL) framework allows learning a shared model collaboratively without data being centralized or shared among data owners. However, we show in this paper that the generalization ability of the joint model is poor on Non-Independent and Non-Identically Distributed (Non-IID) data, particularly when the Federated Averaging (FedAvg) strategy is used due to the weight divergence phenomenon. Hence, we propose a novel boosting algorithm for FL to address both the generalization and gradient leakage issues, as well as achieve faster convergence in gradient-based optimization. In addition, a secure gradient sharing protocol using Homomorphic Encryption (HE) and Differential Privacy (DP) is introduced to defend against gradient leakage attack and avoid pairwise encryption that is not scalable. We demonstrate the proposed Federated Boosting (FedBoosting) method achieves noticeable improvements in both prediction accuracy and run-time efficiency in a visual text recognition task on public benchmark.
翻译:典型的机器学习方法要求为模型培训提供集中的数据,而由于隐私和梯度保护等原因对数据共享实行限制时,这种数据可能是不可能的。最近提出的联邦学习框架允许在数据拥有者不集中或共享数据的情况下,通过协作学习一个共享模式,而数据拥有者不集中或共享数据。然而,我们在本文中表明,联合模型的概括能力在非独立和非同分布(非二二维)数据方面是差强人意的,特别是在由于权重差异现象而采用联邦挥发(FedAvg)战略时。因此,我们提议为联邦学习框架提供一种创新的加速算法,以解决通用和梯度渗漏问题,并在基于梯度的优化方面实现更快的趋同。此外,还引入了一种安全的梯度共享协议,使用单态加密和差异隐私(DP)来防范梯度泄漏攻击,避免无法测量的对齐加密。我们展示了拟议的联邦推动(FedBologing)方法在公共基准的视觉文本识别任务方面明显地改进了预测准确性和实时效率。