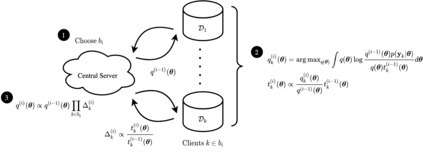
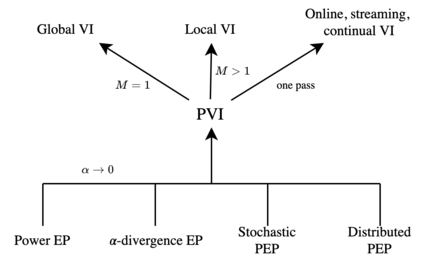
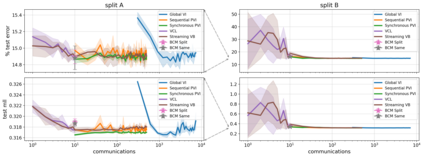
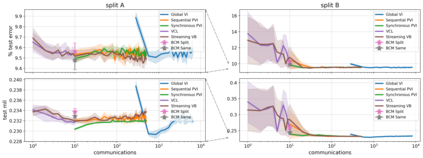
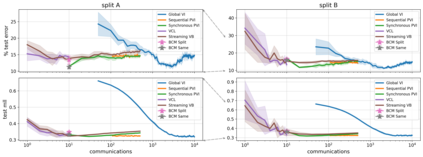
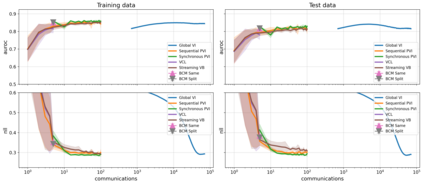
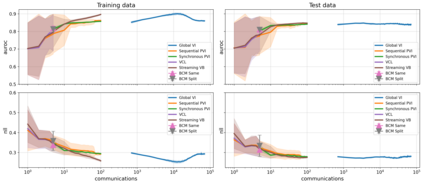
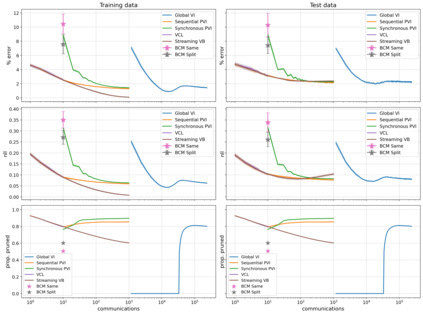
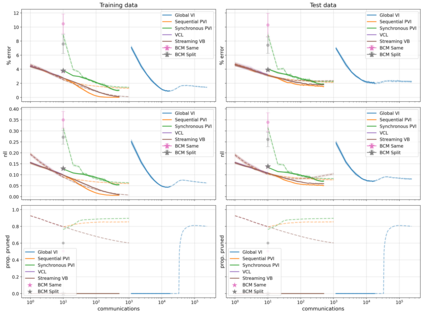
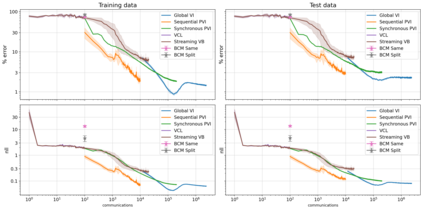
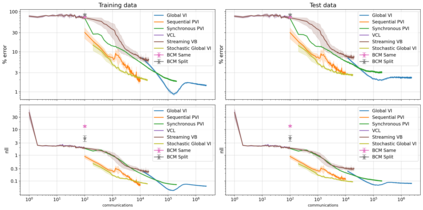
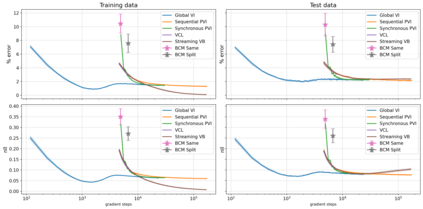
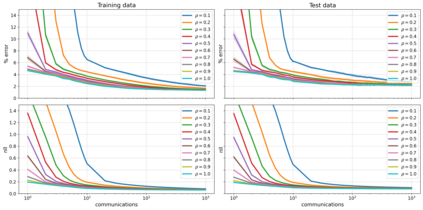
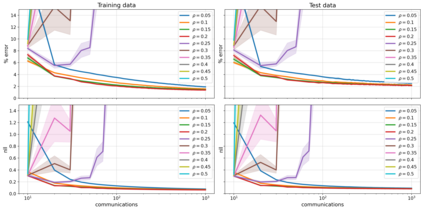
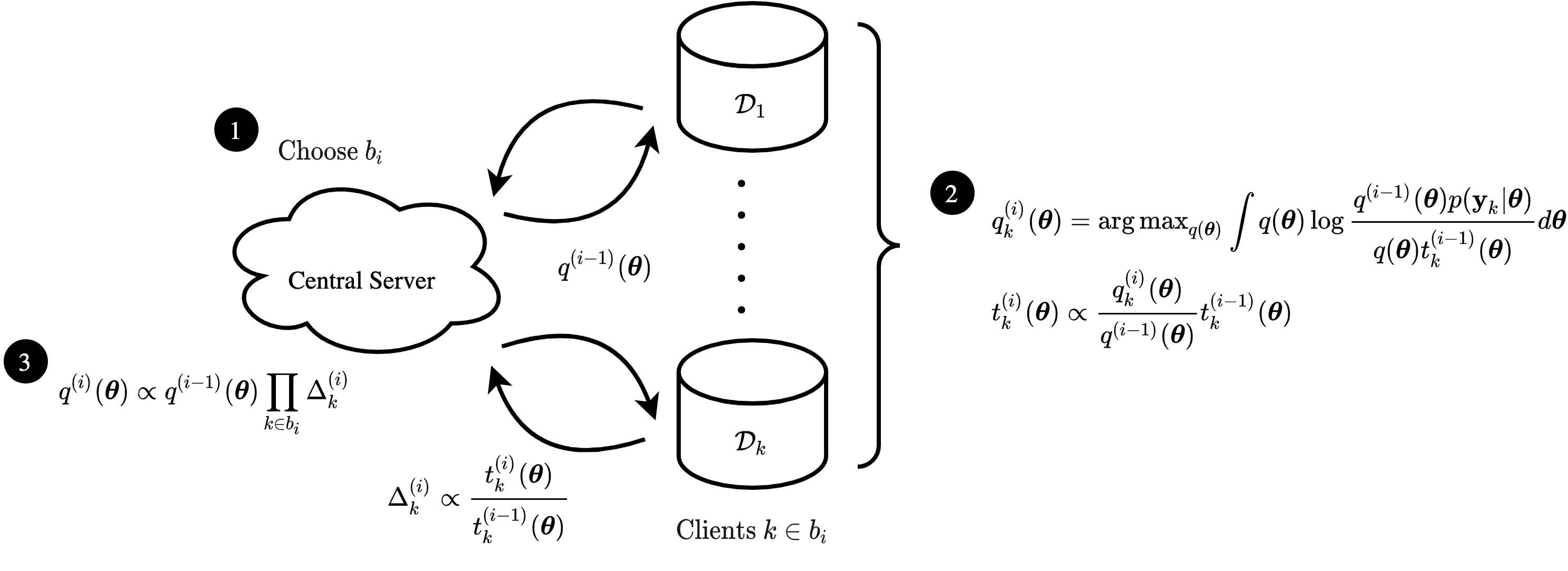
The proliferation of computing devices has brought about an opportunity to deploy machine learning models on new problem domains using previously inaccessible data. Traditional algorithms for training such models often require data to be stored on a single machine with compute performed by a single node, making them unsuitable for decentralised training on multiple devices. This deficiency has motivated the development of federated learning algorithms, which allow multiple data owners to train collaboratively and use a shared model whilst keeping local data private. However, many of these algorithms focus on obtaining point estimates of model parameters, rather than probabilistic estimates capable of capturing model uncertainty, which is essential in many applications. Variational inference (VI) has become the method of choice for fitting many modern probabilistic models. In this paper we introduce partitioned variational inference (PVI), a general framework for performing VI in the federated setting. We develop new supporting theory for PVI, demonstrating a number of properties that make it an attractive choice for practitioners; use PVI to unify a wealth of fragmented, yet related literature; and provide empirical results that showcase the effectiveness of PVI in a variety of federated settings.
翻译:计算机设备的扩散为利用以前无法获取的数据在新的问题领域部署机器学习模型提供了机会。培训这类模型的传统算法往往要求将数据储存在单机上,由单一节点进行计算,使其不适于对多设备进行分散化培训。这一缺陷促使了联邦化学习算法的开发,使多个数据所有者能够合作培训并使用共享模型,同时保持当地数据私密性。然而,许多这些算法侧重于获取模型参数的点估计值,而不是能够捕捉模型不确定性的概率估计值,这在许多应用中至关重要。变数推论(VI)已成为适应许多现代概率模型的首选方法。我们在本文件中引入了分解变推法(PVI),这是在联邦化环境中执行六的通用框架。我们为PVI开发了新的支持理论,表明它对于从业者来说是一个有吸引力的选择;使用PVI将大量零散但相关的文献统一起来;并提供实验结果,展示PVI在各种联邦化环境中的有效性。