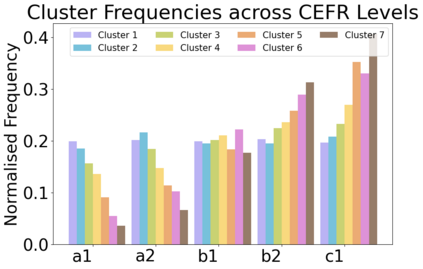
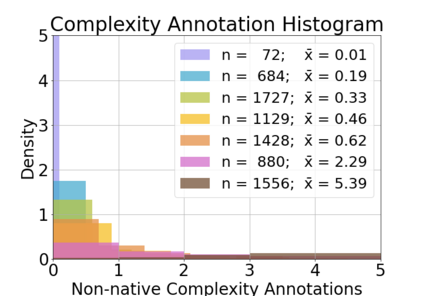
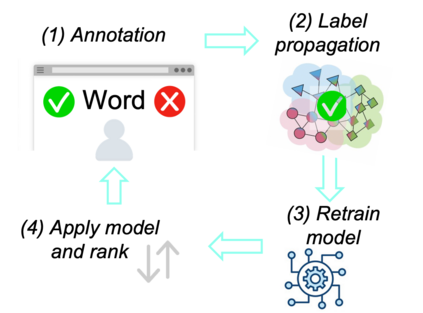
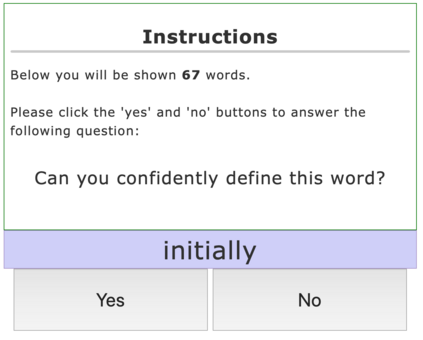
Complex Word Identification (CWI) aims to detect words within a text that a reader may find difficult to understand. It has been shown that CWI systems can improve text simplification, readability prediction and vocabulary acquisition modelling. However, the difficulty of a word is a highly idiosyncratic notion that depends on a reader's first language, proficiency and reading experience. In this paper, we show that personal models are best when predicting word complexity for individual readers. We use a novel active learning framework that allows models to be tailored to individuals and release a dataset of complexity annotations and models as a benchmark for further research.
翻译:复杂单词识别(CWI)的目的是在读者可能发现难以理解的文本中发现词语,已经表明CWI系统可以改进文字简化、可读性预测和词汇获取模型,但是,单词的难度是一个高度特异性的概念,取决于读者的第一语言、熟练程度和阅读经验。在本文中,我们表明个人模型在预测个别读者的文字复杂性时是最好的。我们使用一个新的积极学习框架,使模型适合个人,并发布一套复杂的说明和模型,作为进一步研究的基准。