
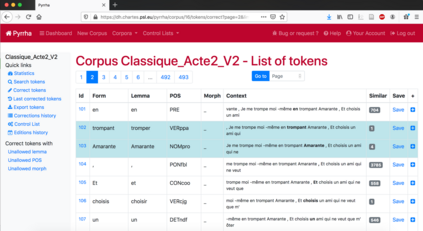
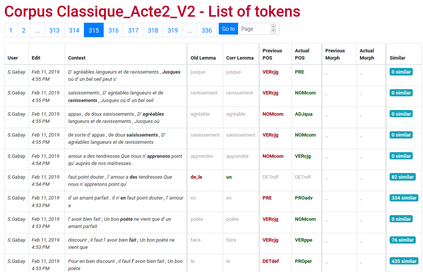
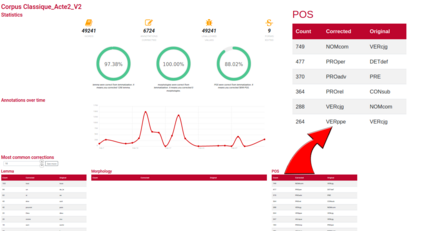
This paper describes the process of building an annotated corpus and training models for classical French literature, with a focus on theatre, and particularly comedies in verse. It was originally developed as a preliminary step to the stylometric analyses presented in Cafiero and Camps [2019]. The use of a recent lemmatiser based on neural networks and a CRF tagger allows to achieve accuracies beyond the current state-of-the art on the in-domain test, and proves to be robust during out-of-domain tests, i.e.up to 20th c.novels.
翻译:本文介绍了为法国古典文学建立附加说明的文稿和培训模式的过程,重点是戏剧,特别是诗中的喜剧,最初是作为Cafiero和Cafiero和Camps[2019]中介绍的测量分析的初步步骤而开发的。使用基于神经网络的最近浸泡剂和通用报告格式调试器,可以超越目前关于内部测试的先进技术,在外部测试(即20c.novels)中证明是稳健的。



相关内容

ACM/IEEE第23届模型驱动工程语言和系统国际会议,是模型驱动软件和系统工程的首要会议系列,由ACM-SIGSOFT和IEEE-TCSE支持组织。自1998年以来,模型涵盖了建模的各个方面,从语言和方法到工具和应用程序。模特的参加者来自不同的背景,包括研究人员、学者、工程师和工业专业人士。MODELS 2019是一个论坛,参与者可以围绕建模和模型驱动的软件和系统交流前沿研究成果和创新实践经验。今年的版本将为建模社区提供进一步推进建模基础的机会,并在网络物理系统、嵌入式系统、社会技术系统、云计算、大数据、机器学习、安全、开源等新兴领域提出建模的创新应用以及可持续性。
官网链接:http://www.modelsconference.org/
相关主题




相关VIP内容
相关资讯
相关论文