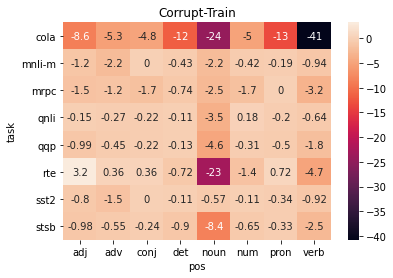
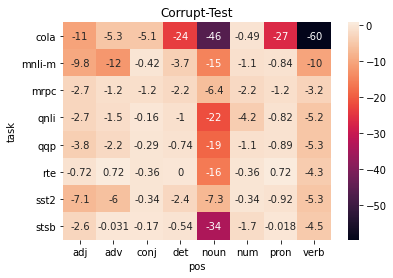
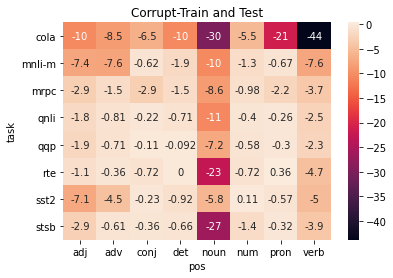
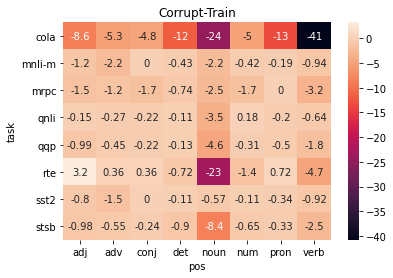
A central question in natural language understanding (NLU) research is whether high performance demonstrates the models' strong reasoning capabilities. We present an extensive series of controlled experiments where pre-trained language models are exposed to data that have undergone specific corruption transformations. The transformations involve removing instances of specific word classes and often lead to non-sensical sentences. Our results show that performance remains high for most GLUE tasks when the models are fine-tuned or tested on corrupted data, suggesting that the models leverage other cues for prediction even in non-sensical contexts. Our proposed data transformations can be used as a diagnostic tool for assessing the extent to which a specific dataset constitutes a proper testbed for evaluating models' language understanding capabilities.
翻译:自然语言理解(NLU)研究的一个中心问题是,高性能是否展示了模型强大的推理能力。我们提出了一系列广泛的受控实验,让经过培训的语文模型接触到经过具体腐败变换的数据。变换涉及删除特定字类的事例,并往往导致非感知性判决。我们的结果表明,当模型对腐败数据进行微调或测试时,大多数GLUE任务的性能仍然很高,这表明模型利用其他提示进行预测,即使在非感知性情况下也是如此。我们提议的数据变换可以作为一种诊断工具,用来评估具体数据集在多大程度上构成评估模型语言理解能力的适当测试台。