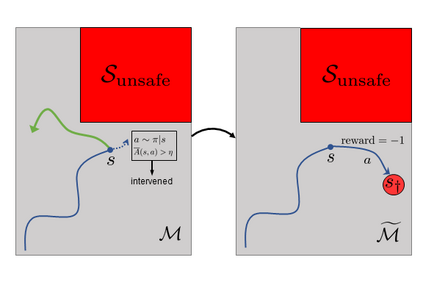
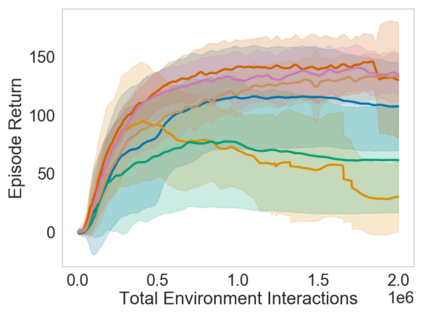
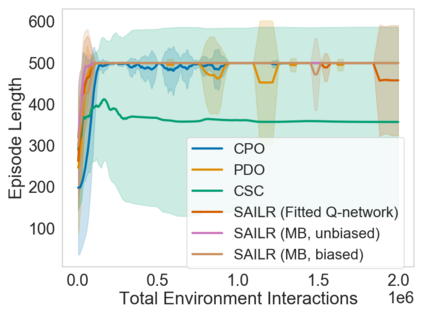
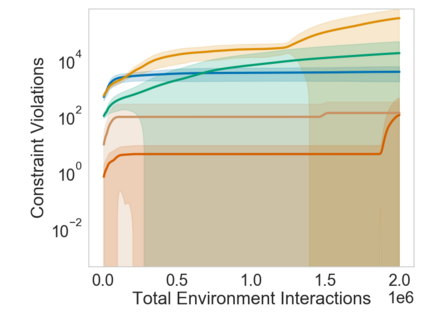
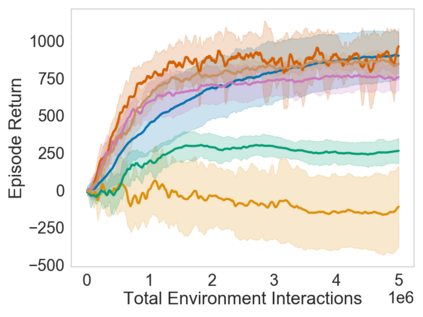
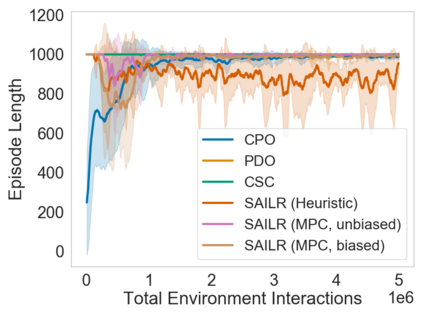
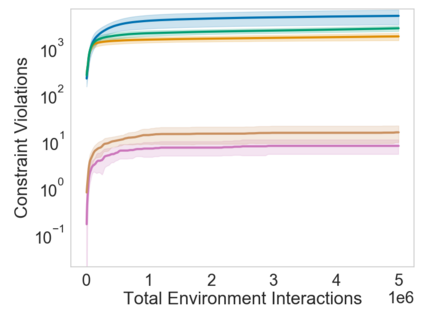
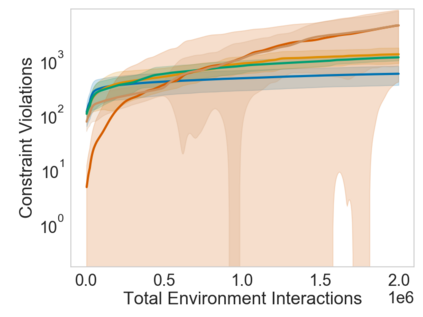
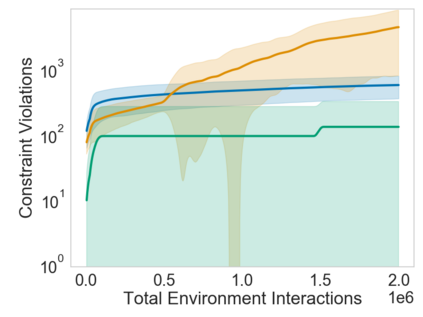
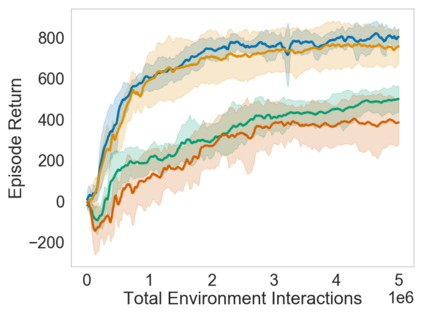
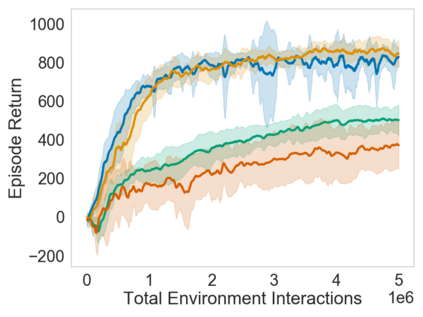
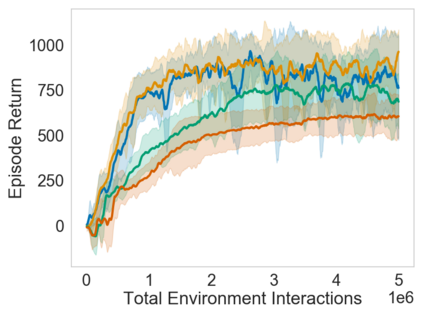
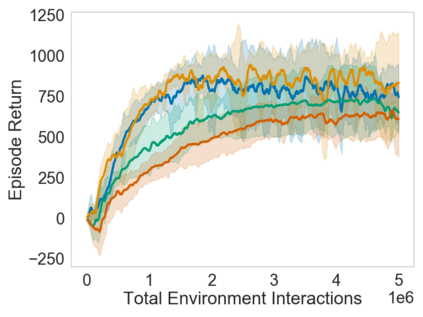
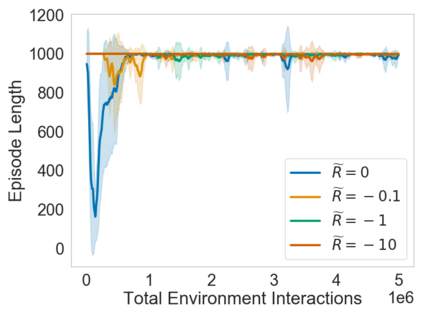
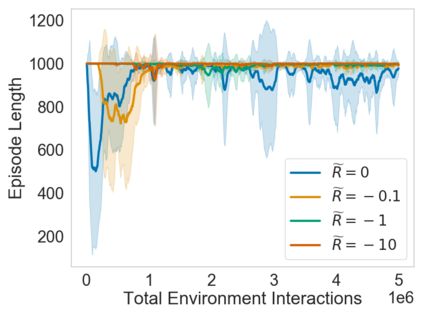
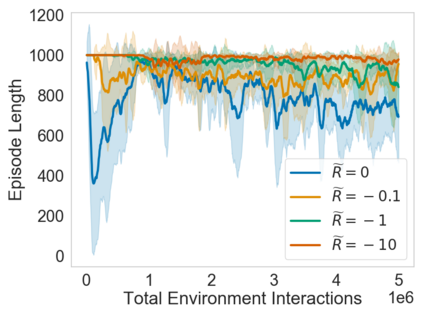
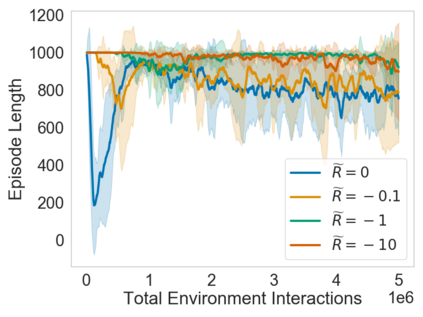
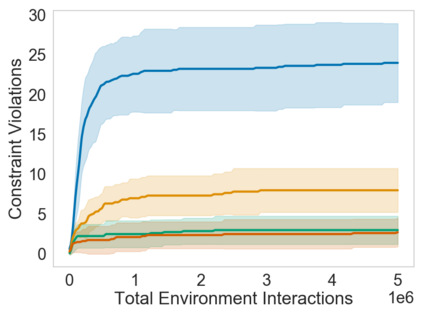
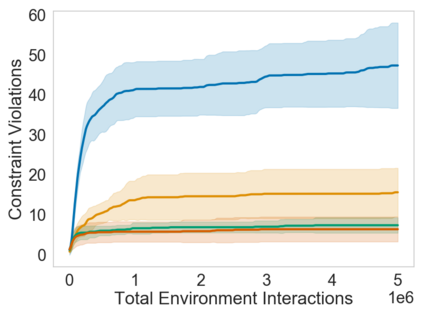
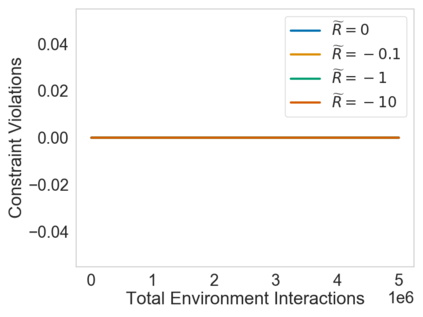
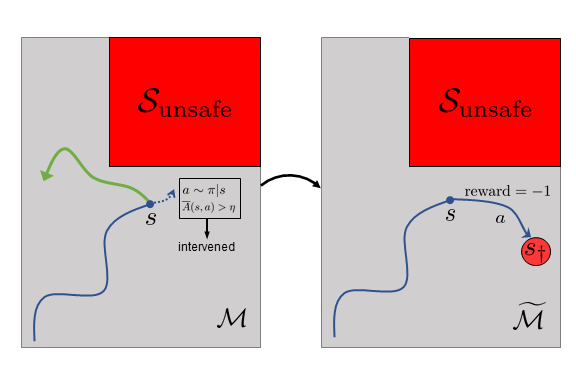
Many sequential decision problems involve finding a policy that maximizes total reward while obeying safety constraints. Although much recent research has focused on the development of safe reinforcement learning (RL) algorithms that produce a safe policy after training, ensuring safety during training as well remains an open problem. A fundamental challenge is performing exploration while still satisfying constraints in an unknown Markov decision process (MDP). In this work, we address this problem for the chance-constrained setting. We propose a new algorithm, SAILR, that uses an intervention mechanism based on advantage functions to keep the agent safe throughout training and optimizes the agent's policy using off-the-shelf RL algorithms designed for unconstrained MDPs. Our method comes with strong guarantees on safety during both training and deployment (i.e., after training and without the intervention mechanism) and policy performance compared to the optimal safety-constrained policy. In our experiments, we show that SAILR violates constraints far less during training than standard safe RL and constrained MDP approaches and converges to a well-performing policy that can be deployed safely without intervention. Our code is available at https://github.com/nolanwagener/safe_rl.
翻译:许多顺序决定问题涉及寻找一种政策,在遵守安全限制的同时,最大限度地提高总报酬,尽管最近许多研究侧重于发展安全强化学习算法,在培训后制定安全的政策,但确保培训期间的安全仍然是一个尚未解决的问题。一个根本的挑战是如何进行探索,同时仍能满足未知的Markov决策程序(MDP)的制约。在这项工作中,我们为受机会限制的环境解决这个问题。我们提出了一个基于优势功能的新算法,即SAILR,使用一种干预机制,在整个培训过程中保证代理人的安全,并利用为不受限制的 MDP 设计的现成RL算法优化代理人的政策。我们的方法在培训和部署期间(即培训之后和没有干预机制)和政策绩效方面都得到了强有力的保障,与最佳的安全约束政策相比。我们实验表明,SAILR在培训期间违反的限制远远少于标准安全RL,并且限制MDP 方法,并结合到一种可以安全部署而不受干预的完善的政策。我们的代码可以在 https://githubr.com/nomalal/safernal上查到。