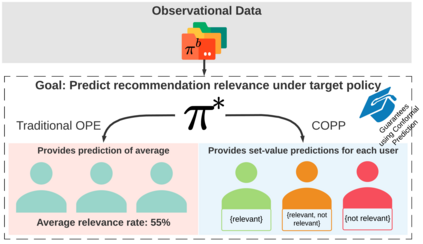
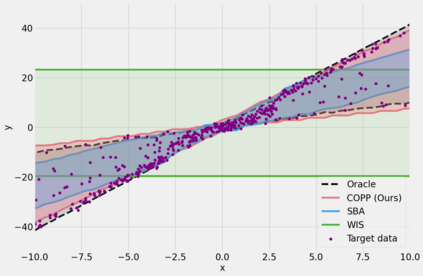
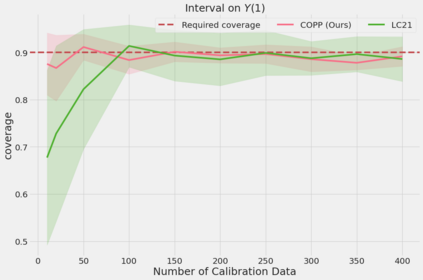
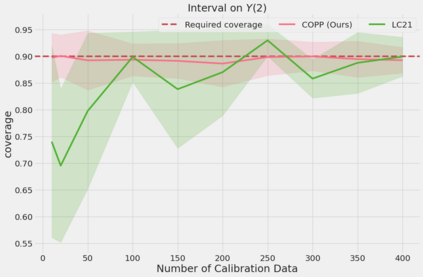
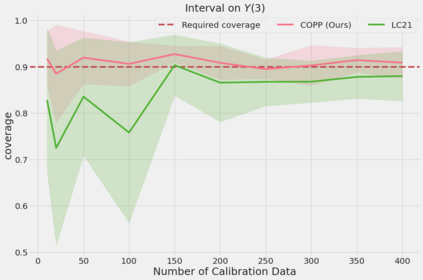
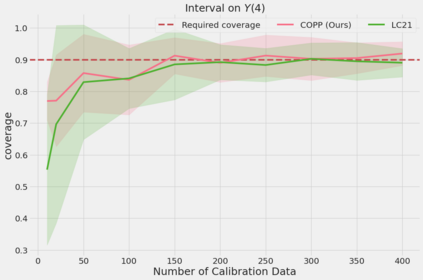
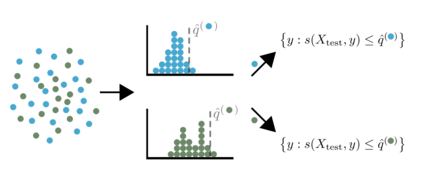
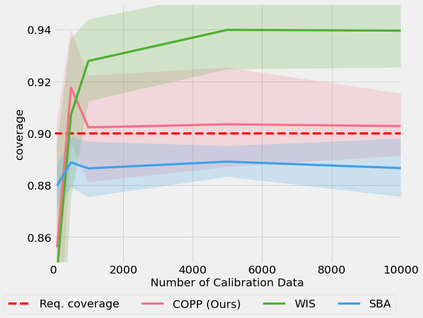
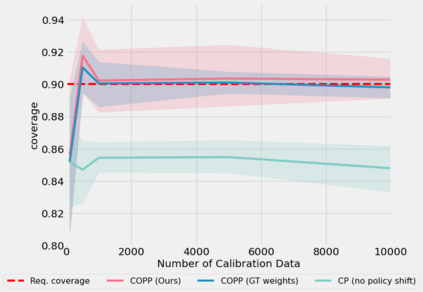
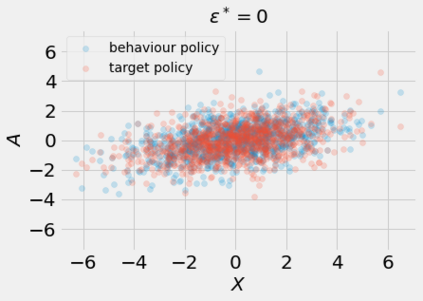
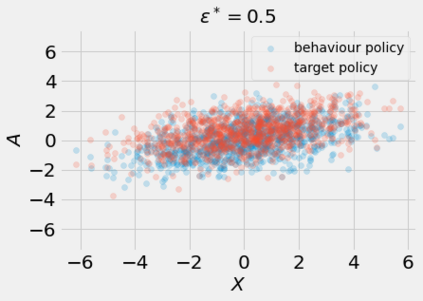
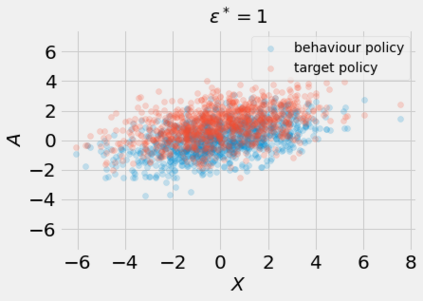
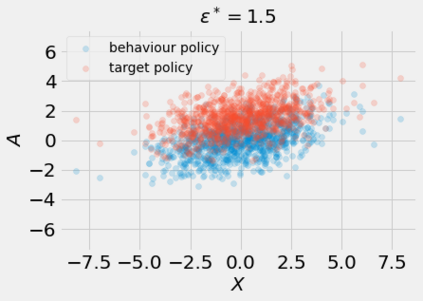
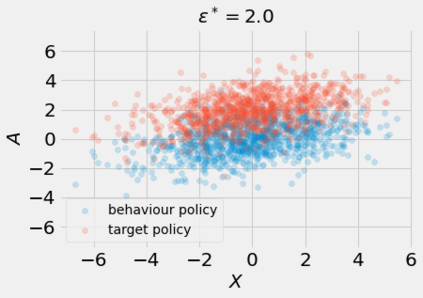
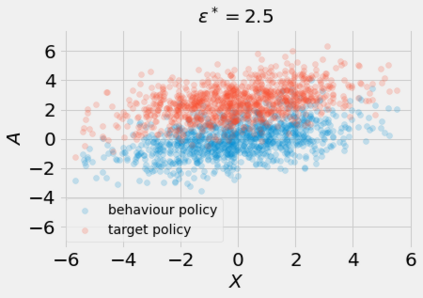
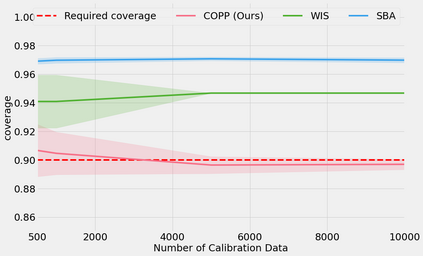
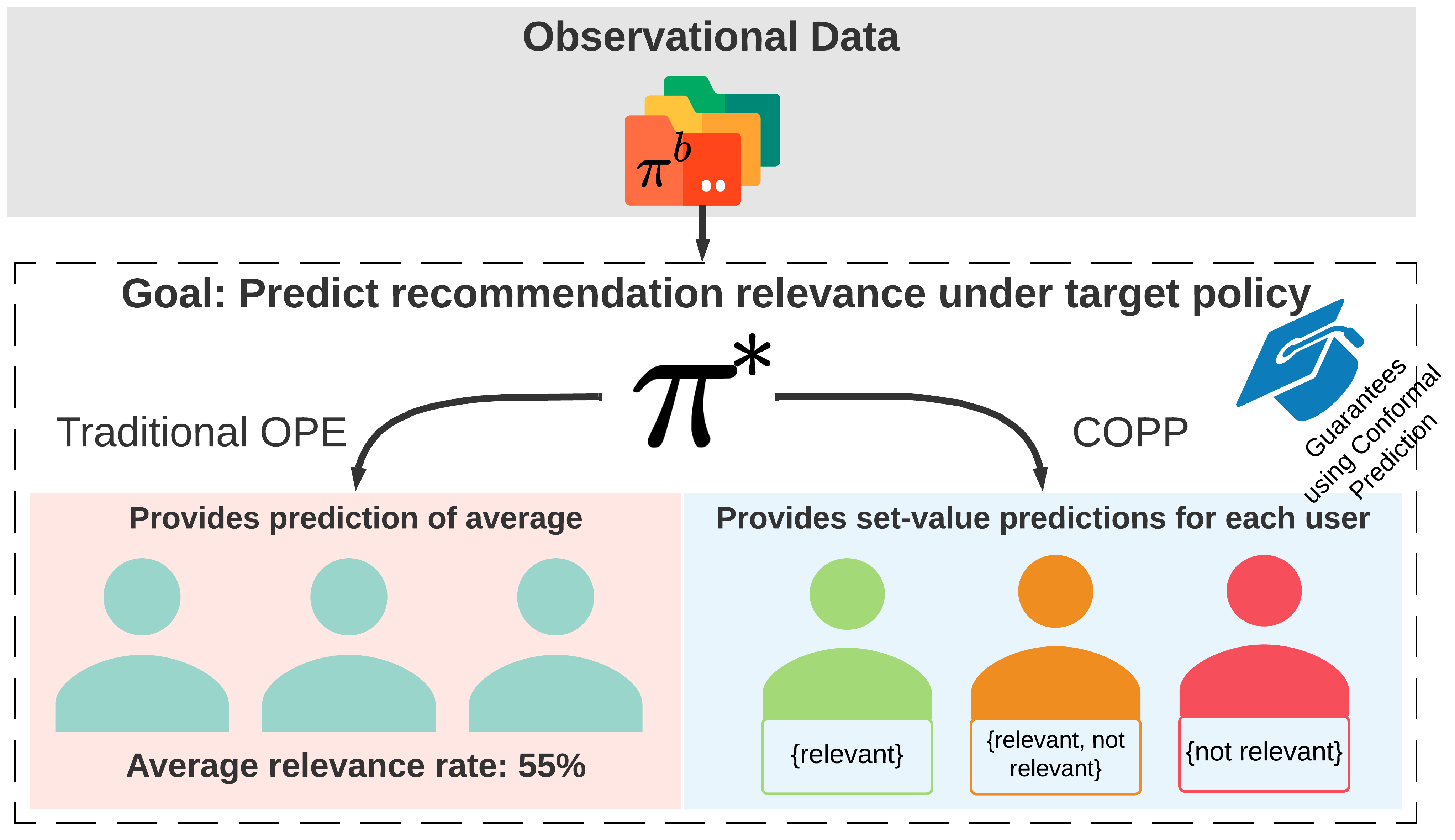
Most off-policy evaluation methods for contextual bandits have focused on the expected outcome of a policy, which is estimated via methods that at best provide only asymptotic guarantees. However, in many applications, the expectation may not be the best measure of performance as it does not capture the variability of the outcome. In addition, particularly in safety-critical settings, stronger guarantees than asymptotic correctness may be required. To address these limitations, we consider a novel application of conformal prediction to contextual bandits. Given data collected under a behavioral policy, we propose \emph{conformal off-policy prediction} (COPP), which can output reliable predictive intervals for the outcome under a new target policy. We provide theoretical finite-sample guarantees without making any additional assumptions beyond the standard contextual bandit setup, and empirically demonstrate the utility of COPP compared with existing methods on synthetic and real-world data.
翻译:大多数针对背景强盗的非政策评价方法都侧重于政策的预期结果,这种估计方法最多只能提供无症状的保证。然而,在许多应用中,这种预期可能不是衡量业绩的最佳尺度,因为它不能反映结果的变异性。此外,在安全危急的环境中,可能需要比无症状的正确性更强有力的保证。为了解决这些限制,我们考虑对背景强盗采用新的一致预测。考虑到根据行为政策收集的数据,我们提议采用 emph{cloral 离政策预测}(COPP ), 根据新的目标政策为结果提供可靠的预测间隔。我们提供理论上的有限抽样保证,而不在标准背景强盗结构之外做任何额外的假设。我们从经验上证明COPP与合成数据和实际世界数据的现有方法相比的效用。