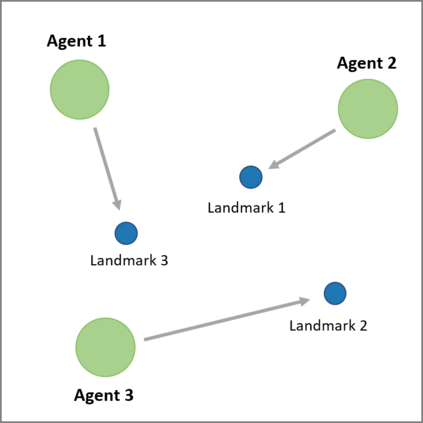
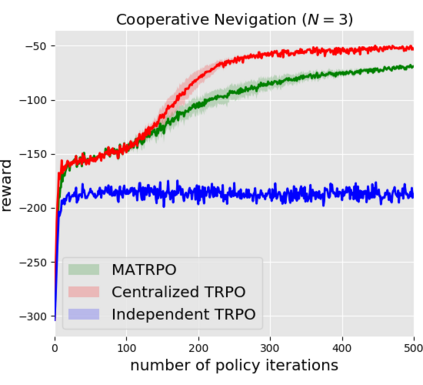
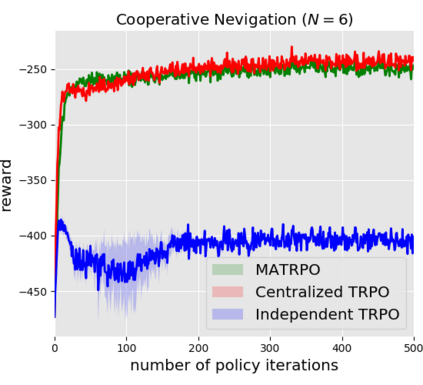
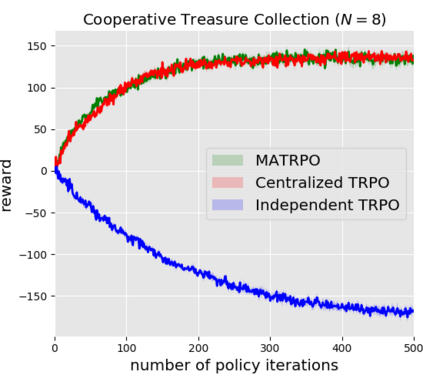
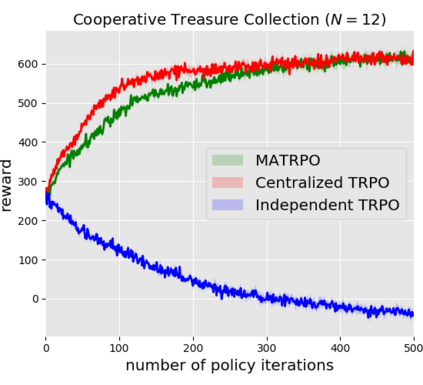
We extend trust region policy optimization (TRPO) to multi-agent reinforcement learning (MARL) problems. We show that the policy update of TRPO can be transformed into a distributed consensus optimization problem for multi-agent cases. By making a series of approximations to the consensus optimization model, we propose a decentralized MARL algorithm, which we call multi-agent TRPO (MATRPO). This algorithm can optimize distributed policies based on local observations and private rewards. The agents do not need to know observations, rewards, policies or value/action-value functions of other agents. The agents only share a likelihood ratio with their neighbors during the training process. The algorithm is fully decentralized and privacy-preserving. Our experiments on two cooperative games demonstrate its robust performance on complicated MARL tasks.
翻译:我们把信任区域政策优化(TRPO)扩大到多试剂强化学习(MARL)问题。我们表明,TRPO的政策更新可以转化为多试剂案例的分布式共识优化问题。通过对共识优化模式进行一系列近似,我们提出了分散的MARL算法,我们称之为多试剂TRPO(MATRPO),这种算法可以优化基于当地观察和私人奖励的分布政策。代理商不需要知道其他代理商的观察、奖励、政策或价值/行动价值。在培训过程中,代理商只与其邻居分享一个可能性比率。算法是完全分散和隐私保护的。我们在两次合作游戏上的实验显示了其在复杂的MARL任务上的有力表现。