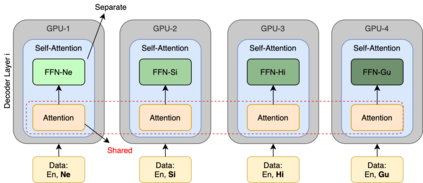
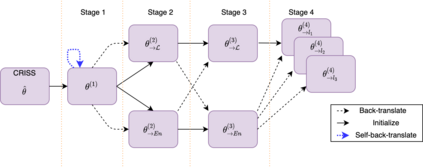
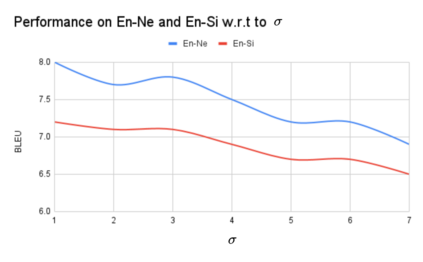
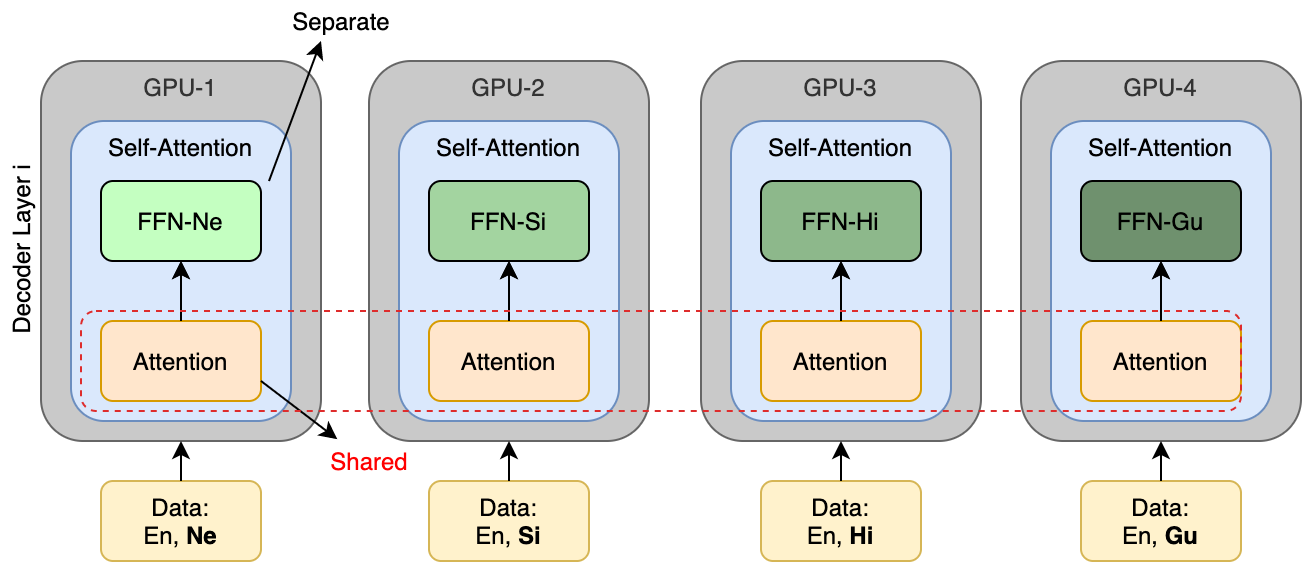
Numerous recent work on unsupervised machine translation (UMT) implies that competent unsupervised translations of low-resource and unrelated languages, such as Nepali or Sinhala, are only possible if the model is trained in a massive multilingual environment, where theses low-resource languages are mixed with high-resource counterparts. Nonetheless, while the high-resource languages greatly help kick-start the target low-resource translation tasks, the language discrepancy between them may hinder their further improvement. In this work, we propose a simple refinement procedure to disentangle languages from a pre-trained multilingual UMT model for it to focus on only the target low-resource task. Our method achieves the state of the art in the fully unsupervised translation tasks of English to Nepali, Sinhala, Gujarati, Latvian, Estonian and Kazakh, with BLEU score gains of 3.5, 3.5, 3.3, 4.1, 4.2, and 3.3, respectively. Our codebase is available at https://github.com/nxphi47/refine_unsup_multilingual_mt
翻译:最近许多关于无人监督的机器翻译(UMT)的工作表明,只有在大量多语言环境中对模型进行培训,而这些低资源语言与高资源语言混杂在一起的情况下,才能对诸如尼泊尔语或僧伽罗语等低资源语言和非相关语言进行胜任的不受监督的翻译。然而,虽然高资源语言极大地帮助启动了目标的低资源翻译任务,但它们之间的语言差异可能妨碍其进一步改进。在这项工作中,我们提议了一个简单的改进程序,将语言与预先培训的多语言的UMT模式区分开来,以便只关注目标的低资源任务。我们的方法在完全不受监督的英语翻译任务中实现了向尼泊尔语、僧伽罗语、古吉拉特语、拉脱维亚语、爱沙尼亚语和哈萨克语的艺术状态,BLEU得分分别为3.5、3.5、3.3、4.1、4.2和3.3。我们的代码库可在 https://github.com/nxphi47/refine_unsup_multol语_mt上查阅。