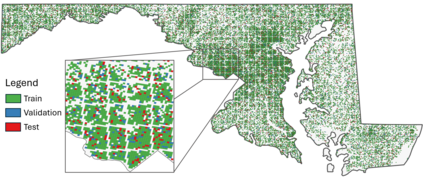
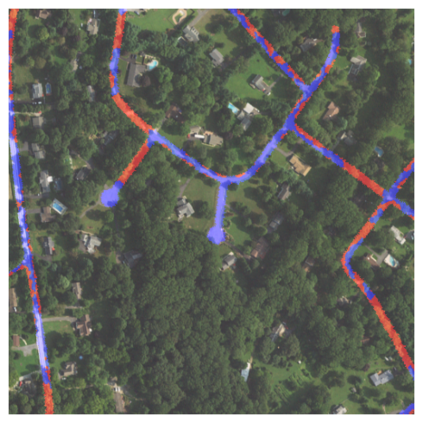
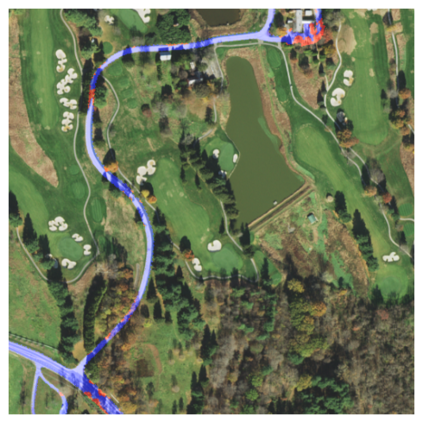
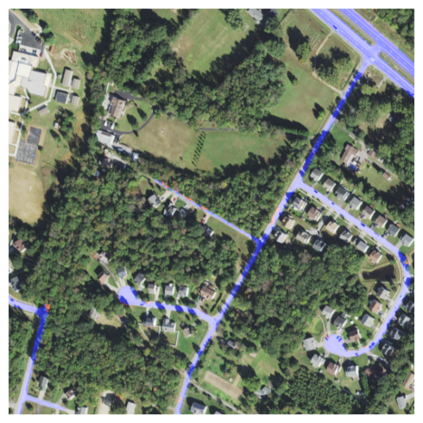
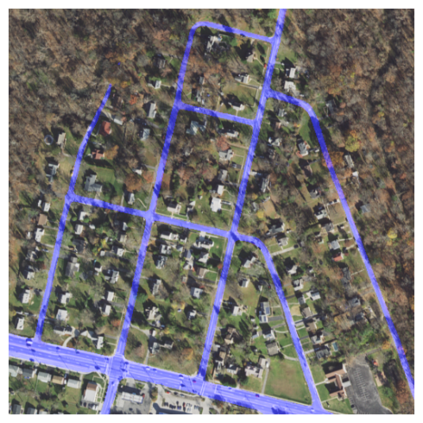
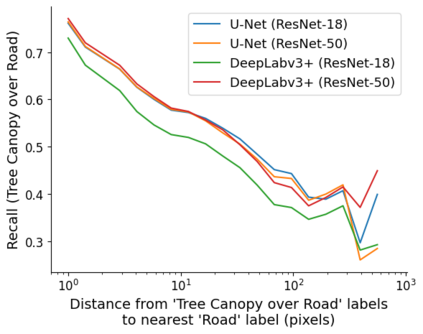
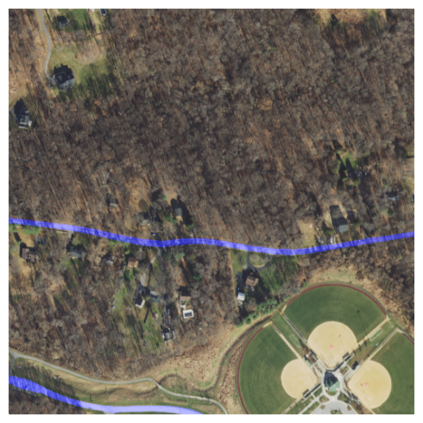
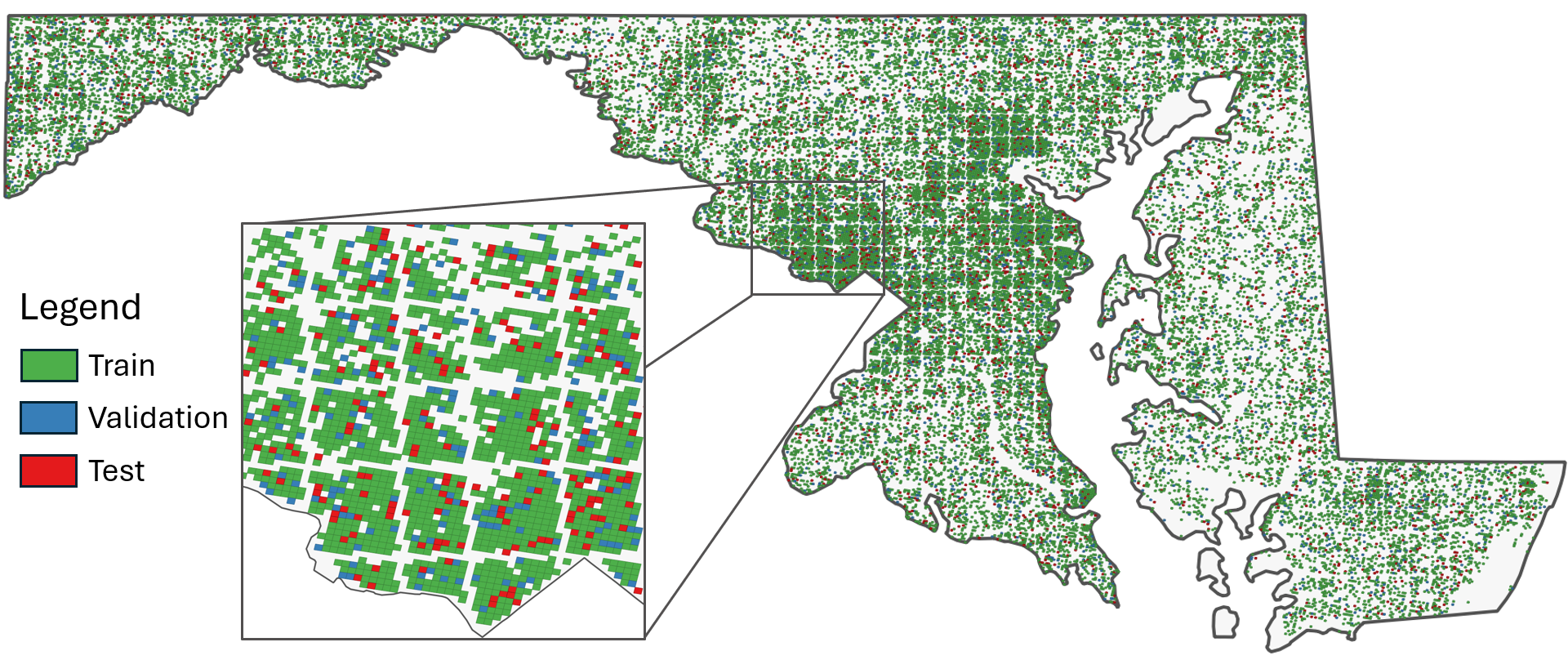
Fully understanding a complex high-resolution satellite or aerial imagery scene often requires spatial reasoning over a broad relevant context. The human object recognition system is able to understand object in a scene over a long-range relevant context. For example, if a human observes an aerial scene that shows sections of road broken up by tree canopy, then they will be unlikely to conclude that the road has actually been broken up into disjoint pieces by trees and instead think that the canopy of nearby trees is occluding the road. However, there is limited research being conducted to understand long-range context understanding of modern machine learning models. In this work we propose a road segmentation benchmark dataset, Chesapeake Roads Spatial Context (RSC), for evaluating the spatial long-range context understanding of geospatial machine learning models and show how commonly used semantic segmentation models can fail at this task. For example, we show that a U-Net trained to segment roads from background in aerial imagery achieves an 84% recall on unoccluded roads, but just 63.5% recall on roads covered by tree canopy despite being trained to model both the same way. We further analyze how the performance of models changes as the relevant context for a decision (unoccluded roads in our case) varies in distance. We release the code to reproduce our experiments and dataset of imagery and masks to encourage future research in this direction -- https://github.com/isaaccorley/ChesapeakeRSC.
翻译:暂无翻译