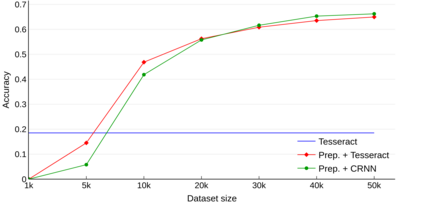
Optical character recognition (OCR) is a widely used pattern recognition application in numerous domains. There are several feature-rich, general-purpose OCR solutions available for consumers, which can provide moderate to excellent accuracy levels. However, accuracy can diminish with difficult and uncommon document domains. Preprocessing of document images can be used to minimize the effect of domain shift. In this paper, a novel approach is presented for creating a customized preprocessor for a given OCR engine. Unlike the previous OCR agnostic preprocessing techniques, the proposed approach approximates the gradient of a particular OCR engine to train a preprocessor module. Experiments with two datasets and two OCR engines show that the presented preprocessor is able to improve the accuracy of the OCR up to 46% from the baseline by applying pixel-level manipulations to the document image. The implementation of the proposed method and the enhanced public datasets are available for download.
翻译:光学字符识别(OCR)是许多领域广泛使用的模式识别应用。消费者可以使用几种具有地貌特性的通用的OCR解决方案,这些解决方案可以提供中度至极佳的精确度。然而,精确度会随着困难和不寻常的文件域而降低。文件图像的预处理可以用来最大限度地减少域转移的影响。在本文中,提出了为特定光化光化字符识别引擎创建定制预处理器的新办法。与先前的OCR随机预处理技术不同,拟议办法接近用于培训预处理模块的特定OCR引擎的梯度。用两个数据集和两个OCR引擎进行的实验显示,所提出的预处理器能够通过对文件图像应用像素级操作,从基线上提高OCR的准确度,达到46%。可以下载拟议的方法和强化的公共数据集。