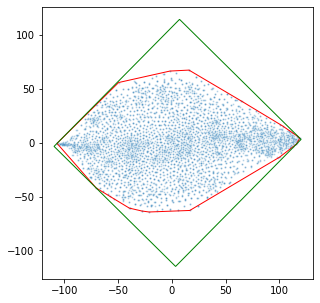
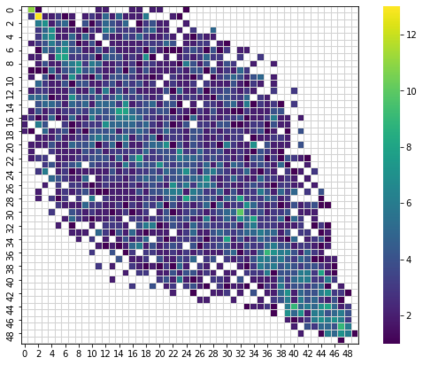
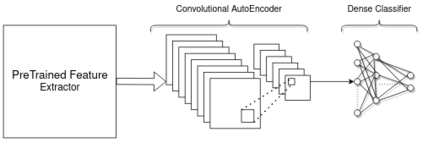
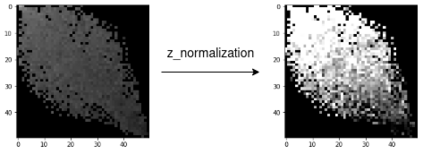Knowledge is acquired by humans through experience, and no boundary is set between the kinds of knowledge or skill levels we can achieve on different tasks at the same time. When it comes to Neural Networks, that is not the case. The breakthroughs in the field are extremely task and domain-specific. Vision and language are dealt with in separate manners, using separate methods and different datasets. Current text classification methods, mostly rely on obtaining contextual embeddings for input text samples, then training a classifier on the embedded dataset. Transfer learning in Language-related tasks in general, is heavily used in obtaining the contextual text embeddings for the input samples. In this work, we propose to use the knowledge acquired by benchmark Vision Models which are trained on ImageNet to help a much smaller architecture learn to classify text. A data transformation technique is used to create a new image dataset, where each image represents a sentence embedding from the last six layers of BERT, projected on a 2D plane using a t-SNE based method. We trained five models containing early layers sliced from vision models which are pretrained on ImageNet, on the created image dataset for the IMDB dataset embedded with the last six layers of BERT. Despite the challenges posed by the very different datasets, experimental results achieved by this approach which links large pretrained models on both language and vision, are very promising, without employing compute resources. Specifically, Sentiment Analysis is achieved by five different models on the same image dataset obtained after BERT embeddings are transformed into gray scale images. Index Terms: BERT, Convolutional Neural Networks, Domain Adaptation, image classification, Natural Language Processing, t-SNE, text classification, Transfer Learning
翻译:人类通过经验获得知识, 并且没有划定我们在同一时间可以实现的不同任务的知识或技能水平之间的界限。 当涉及到神经网络时, 情况并非如此。 实地的突破是极其艰巨的任务和特定域的。 视野和语言以不同的方式处理, 使用不同的方法和不同的数据集。 当前文本分类方法, 大多依靠获得输入文本样本的背景嵌入, 然后在嵌入的数据集上培训一个分类器。 语言相关任务的一般传输学习, 大量用于为输入样本获取背景文本嵌入。 在这项工作中, 我们提议使用基准愿景模型获得的知识, 这些模型是在图像网络上培训的, 以帮助更小得多的架构来对文本进行分类。 数据转换技术被用于创建新的图像数据集, 其中每张图像代表从最后六层BERT中嵌入的句子, 以t- SNE 方法在2D 平面平面上预测。 语言相关任务转换的指数, 我们培训了5个模型, 包含预在图像网络上嵌入的图像缩略图, 在创建的“ 内” 服务器上, 在创建的“ Brealder le le lead level lection lection lection leveldeal ”, 在创建的“ lavel lavel 6 laveild laveld laveal laveld” 数据” 方法上, laveld