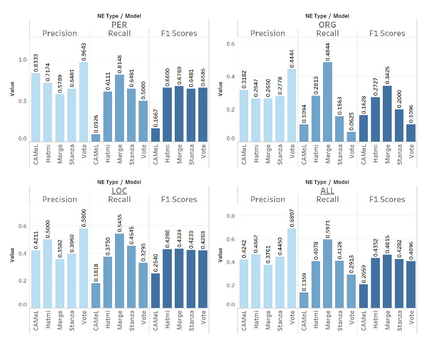
The main objective of this paper is to compare and evaluate the performances of three open Arabic NER tools: CAMeL, Hatmi, and Stanza. We collected a corpus consisting of 30 articles written in MSA and manually annotated all the entities of the person, organization, and location types at the article (document) level. Our results suggest a similarity between Stanza and Hatmi with the latter receiving the highest F1 score for the three entity types. However, CAMeL achieved the highest precision values for names of people and organizations. Following this, we implemented a "merge" method that combined the results from the three tools and a "vote" method that tagged named entities only when two of the three identified them as entities. Our results showed that merging achieved the highest overall F1 scores. Moreover, merging had the highest recall values while voting had the highest precision values for the three entity types. This indicates that merging is more suitable when recall is desired, while voting is optimal when precision is required. Finally, we collected a corpus of 21,635 articles related to COVID-19 and applied the merge and vote methods. Our analysis demonstrates the tradeoff between precision and recall for the two methods.
翻译:本文的主要目的是比较和评估三种开放的阿拉伯净入学率工具:CAMEL、Hatmi和Stanza的绩效。我们收集了一套由30篇文章组成的材料,在《管理事务协议》中写了30篇文章,并在文章(文件)一级人工加注了所有个人、组织和地点类型。我们的结果表明,Stanza和Hatmi与在三种实体类型中获得最高F1分的Hatmi之间有相似之处。然而,CAMEL达到了人员和组织名称的最高精确值。随后,我们采用了一种“合并”方法,将这三种工具的结果和“投票”方法结合起来,在三个实体中,有2个被确定为实体时加注了名字。我们的分析表明,合并后加得最高值,而投票时有三种实体类型的最高精确值。这表明,合并更合适时是值得回顾的,而需要时投票是最佳的。最后,我们收集了21,635篇与COVID-19有关的文章,并应用了合并和投票方法。我们的分析表明两种方法的精确度和回顾之间的权衡。