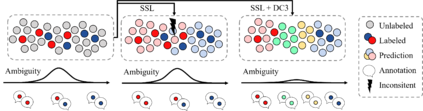
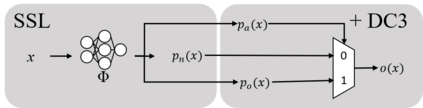
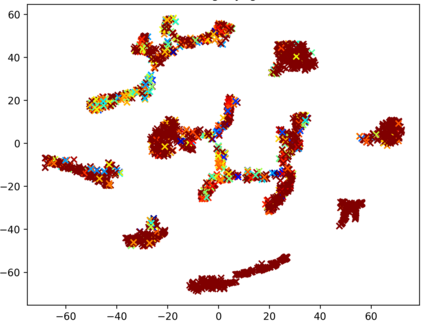
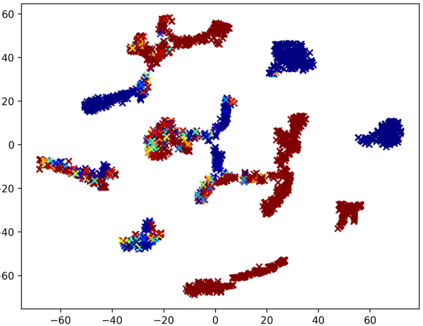
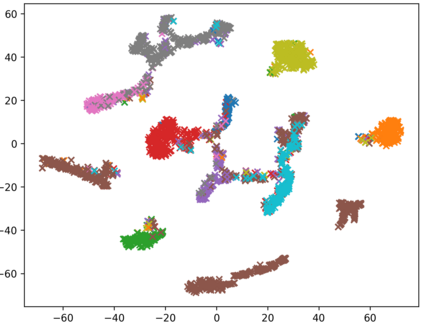
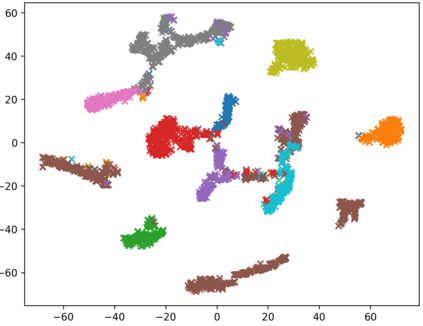
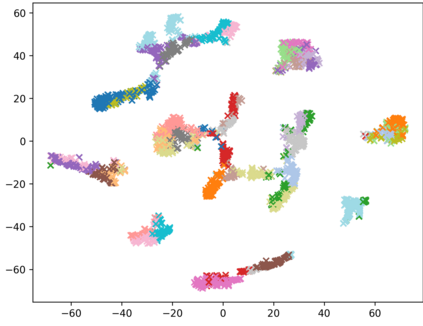
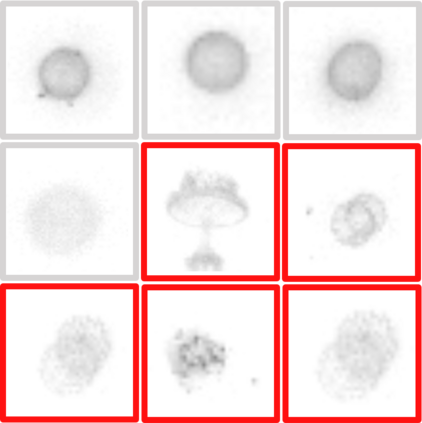
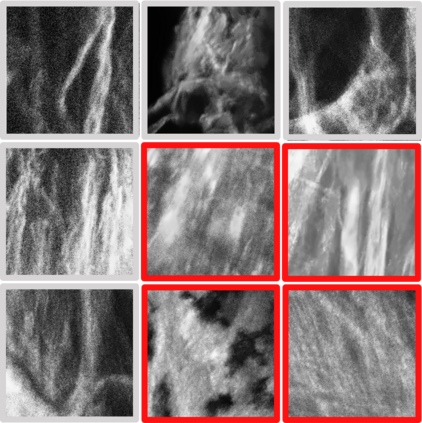
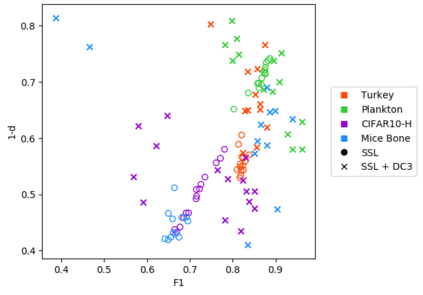
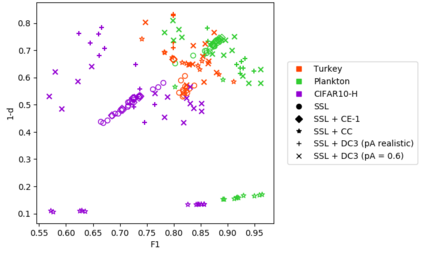
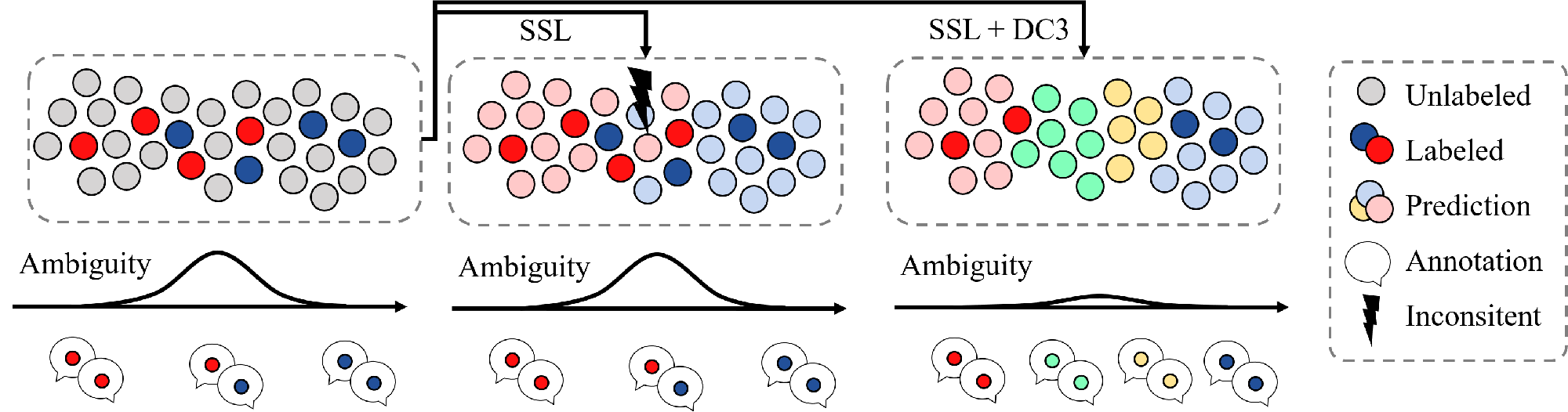
Consistently high data quality is essential for the development of novel loss functions and architectures in the field of deep learning. The existence of such data and labels is usually presumed, while acquiring high-quality datasets is still a major issue in many cases. In real-world datasets we often encounter ambiguous labels due to subjective annotations by annotators. In our data-centric approach, we propose a method to relabel such ambiguous labels instead of implementing the handling of this issue in a neural network. A hard classification is by definition not enough to capture the real-world ambiguity of the data. Therefore, we propose our method "Data-Centric Classification & Clustering (DC3)" which combines semi-supervised classification and clustering. It automatically estimates the ambiguity of an image and performs a classification or clustering depending on that ambiguity. DC3 is general in nature so that it can be used in addition to many Semi-Supervised Learning (SSL) algorithms. On average, this results in a 7.6% better F1-Score for classifications and 7.9% lower inner distance of clusters across multiple evaluated SSL algorithms and datasets. Most importantly, we give a proof-of-concept that the classifications and clusterings from DC3 are beneficial as proposals for the manual refinement of such ambiguous labels. Overall, a combination of SSL with our method DC3 can lead to better handling of ambiguous labels during the annotation process.
翻译:一贯的高质量数据质量对于在深层学习领域开发新的损失函数和结构至关重要。 通常假定存在这类数据和标签,而获取高质量的数据集仍然是许多情况下的一个主要问题。 在现实世界的数据集中,我们经常会遇到因注释者的主观说明而导致的模糊标签。 在以数据为中心的方法中,我们提出一种方法来重新标注这种模糊标签,而不是在神经网络中实施处理该问题的方法。根据定义,硬分类并不足以捕捉数据的真实世界模糊性。因此,我们提出了“数据目录分类和分类组合(DC3)”的方法,该方法将半监督分类和分组结合起来。在现实世界的数据集中,它自动估计了图像的模糊性,并根据这种模糊性进行分类或组合。 DC3是一般性的,因此,除了许多半超常学习(SSL)的算法外,我们还可以使用它来重新标注。 平均而言,用于分类的7.6% F1-S-STR和7.9%的更低内部距离,跨已评估过的SL3 的分类和总体数据分类方法中,我们可以用一个更好的标定的标签方法来验证。