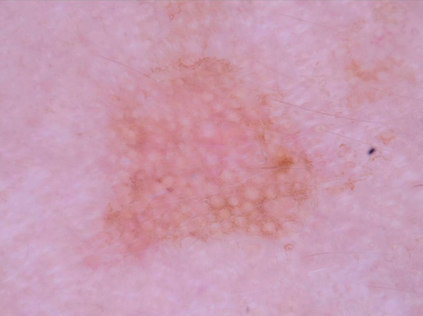
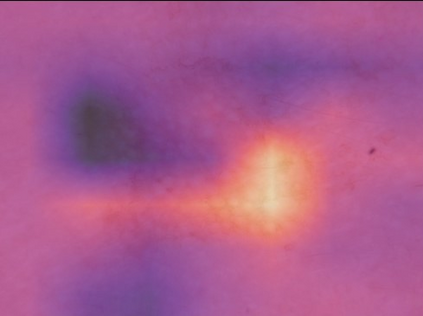
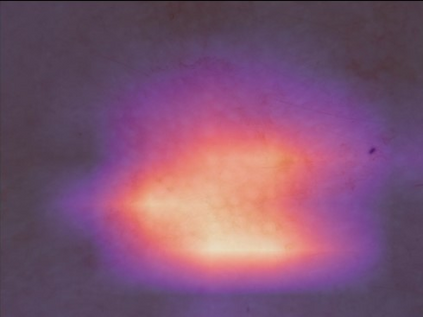
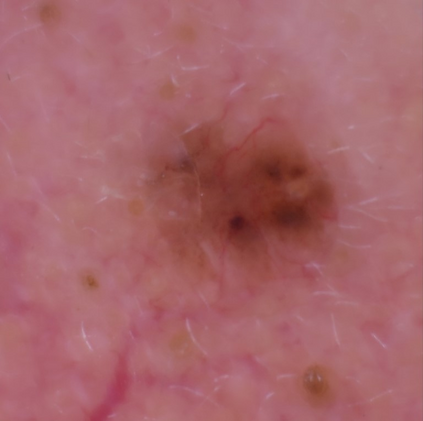
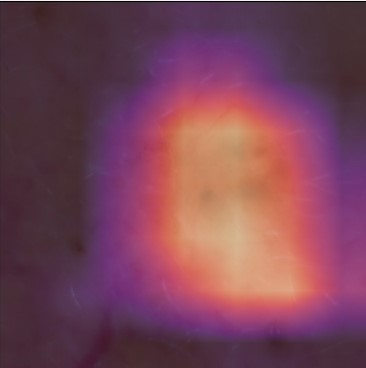
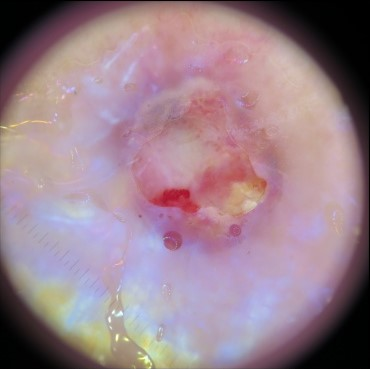
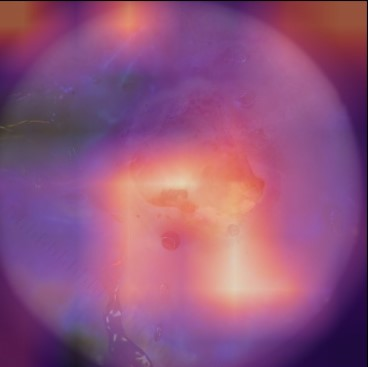
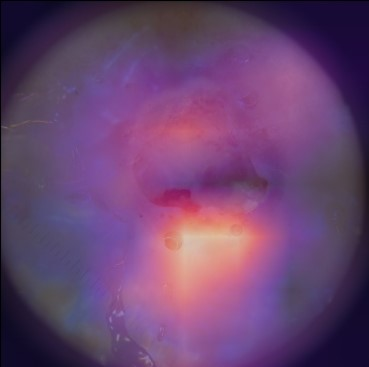
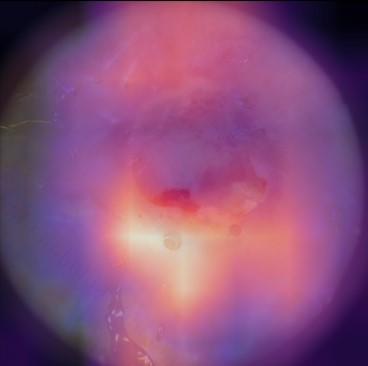
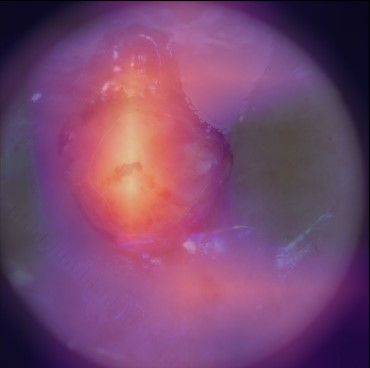
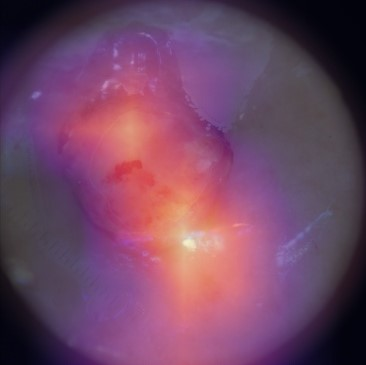
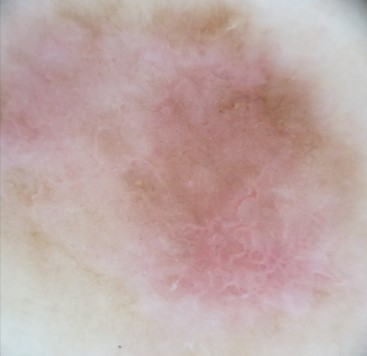
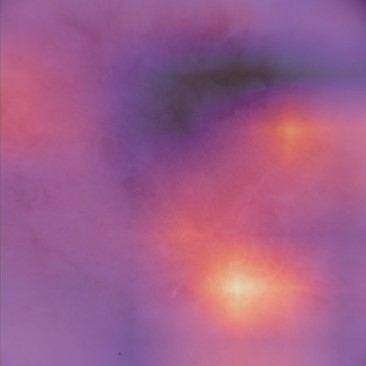
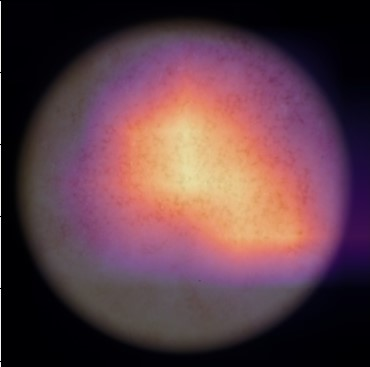
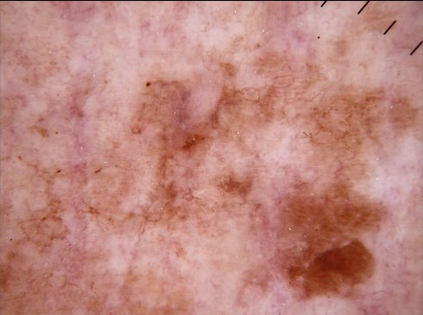
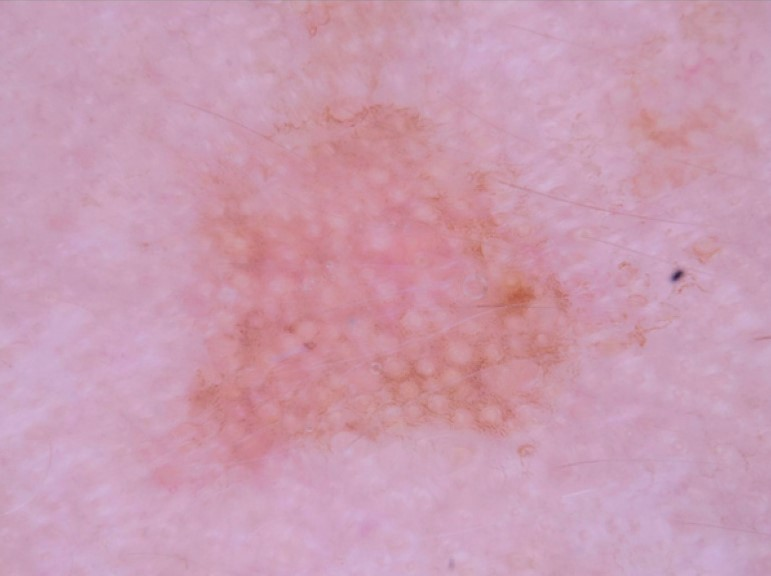
State-of-the-art deep learning approaches for skin lesion recognition often require pretraining on larger and more varied datasets, to overcome the generalization limitations derived from the reduced size of the skin lesion imaging datasets. ImageNet is often used as the pretraining dataset, but its transferring potential is hindered by the domain gap between the source dataset and the target dermatoscopic scenario. In this work, we introduce a novel pretraining approach that sequentially trains a series of Self-Supervised Learning pretext tasks and only requires the unlabeled skin lesion imaging data. We present a simple methodology to establish an ordering that defines a pretext task curriculum. For the multi-class skin lesion classification problem, and ISIC-2019 dataset, we provide experimental evidence showing that: i) a model pretrained by a curriculum of pretext tasks outperforms models pretrained by individual pretext tasks, and ii) a model pretrained by the optimal pretext task curriculum outperforms a model pretrained on ImageNet. We demonstrate that this performance gain is related to the fact that the curriculum of pretext tasks better focuses the attention of the final model on the skin lesion. Beyond performance improvement, this strategy allows for a large reduction in the training time with respect to ImageNet pretraining, which is especially advantageous for network architectures tailored for a specific problem.
翻译:在皮肤损伤识别方面,最先进的深层学习方法往往要求就更大规模、更多样化的数据集进行预先培训,以克服因皮肤损伤成像数据集规模缩小而产生的一般限制。图像网通常用作预培训数据集,但其转移潜力受到源数据集和目标皮肤科情景之间领域差距的阻碍。在这项工作中,我们采用新的预培训方法,按顺序培训一系列自我监视学习的借口任务,只要求不贴标签的皮肤损伤成像数据。我们提出了一个简单的方法,以建立一个命令来界定一个托辞任务课程。对于多级皮肤损伤分类问题和ISIC-2019数据集,我们提供了实验性证据,表明:一) 由一个托辞任务课程比个人托辞任务预先训练的模式更优于模型,这在图像网上培训模型比模型先培训更优于模型。我们证明,这一业绩收益与以下事实有关:一个更突出托辞任务的重点,即界定一个托辞任务课程,确定一个托辞任务大纲。对于多级皮肤损伤分类问题,以及ISIC-2019数据集,我们提供了实验性地证明:一模型预设的模型的模型预设型模型预训练模型,使得最终的升级模型能够改进。