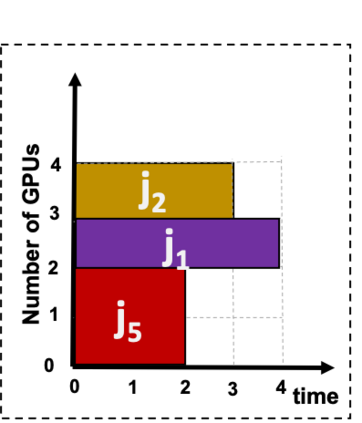
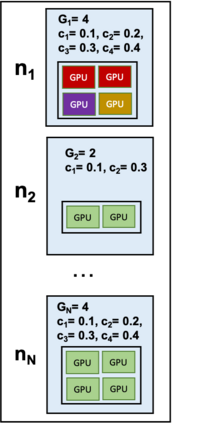
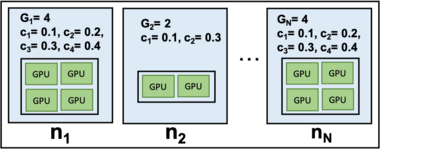
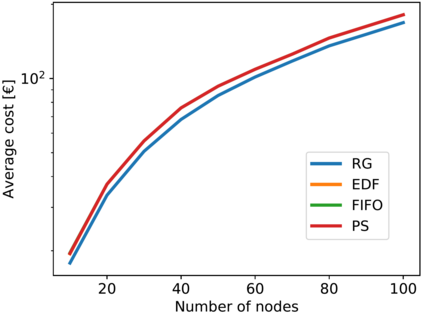
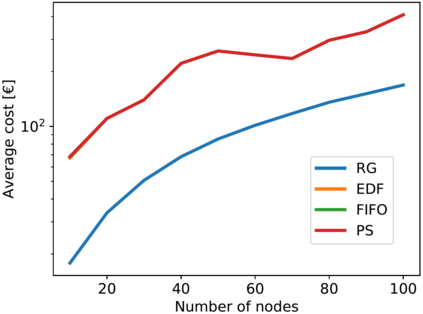
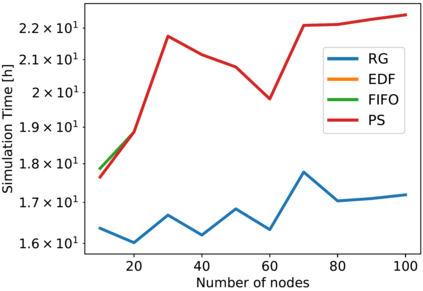
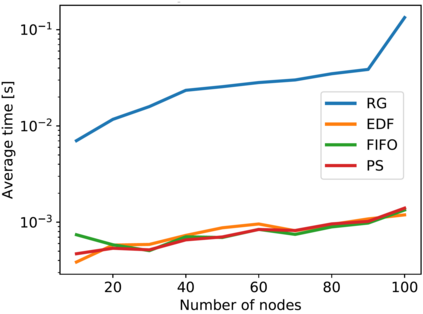
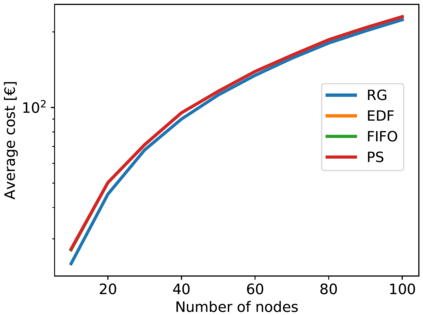
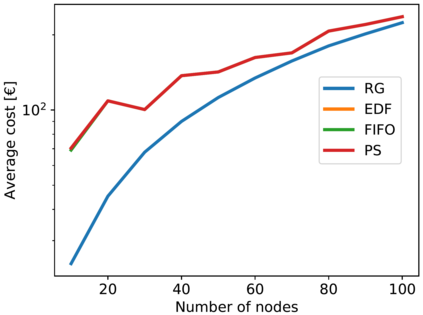
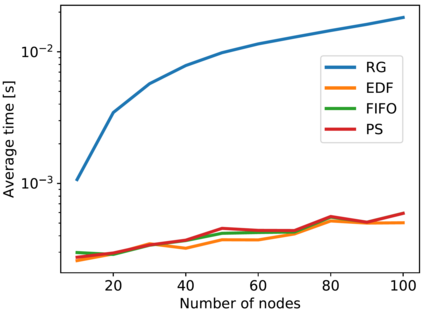
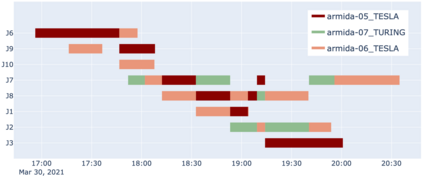
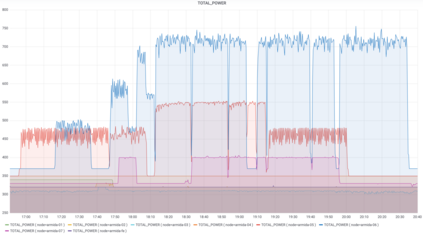
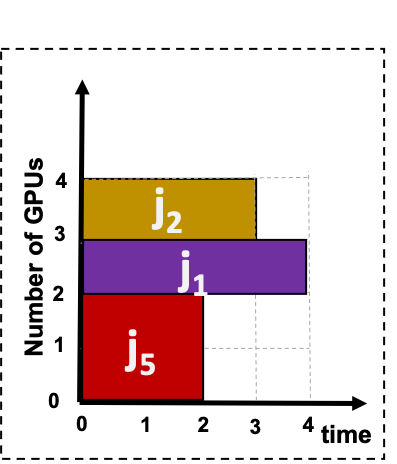
Artificial Intelligence (AI) and Deep Learning (DL) algorithms are currently applied to a wide range of products and solutions. DL training jobs are highly resource demanding and they experience great benefits when exploiting AI accelerators (e.g., GPUs). However, the effective management of GPU-powered clusters comes with great challenges. Among these, efficient scheduling and resource allocation solutions are crucial to maximize performance and minimize Data Centers operational costs. In this paper we propose ANDREAS, an advanced scheduling solution that tackles these problems jointly, aiming at optimizing DL training runtime workloads and their energy consumption in accelerated clusters. Experiments based on simulation demostrate that we can achieve a cost reduction between 30 and 62% on average with respect to first-principle methods while the validation on a real cluster shows a worst case deviation below 13% between actual and predicted costs, proving the effectiveness of ANDREAS solution in practical scenarios.
翻译:人工智能(AI)和深学习(DL)算法目前适用于广泛的产品和解决方案。DL培训工作需要大量资源,在利用AI加速器(例如GPUs)时,他们受益匪浅。然而,有效管理GPU动力集群带来了巨大的挑战,其中高效的时间安排和资源分配解决方案对于最大限度地提高业绩和最大限度地减少数据中心的业务费用至关重要。本文建议ANDREAS采用一个先进的时间安排解决方案,联合解决这些问题,目的是优化DL培训运行时的工作量及其在加速集群中的能源消耗。基于模拟实验,我们可以平均降低30至62%的成本,在第一原则方法方面,而对于实际集群的验证显示实际成本和预测成本之间的最差的情况差异在13%以下,从而证明ANDREAS解决方案在实际情景中的有效性。