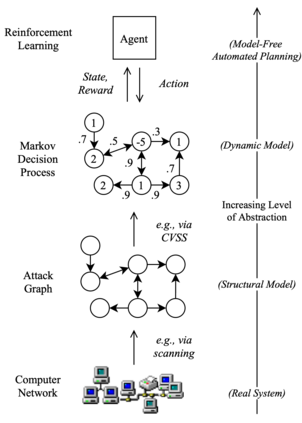
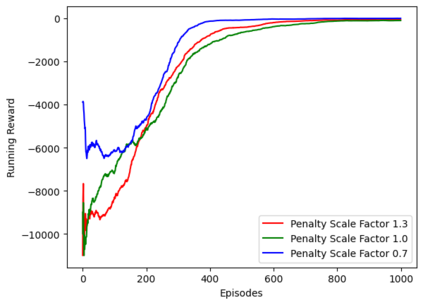
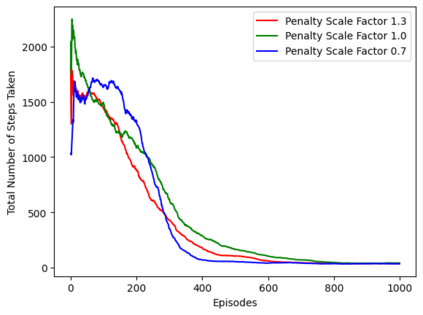
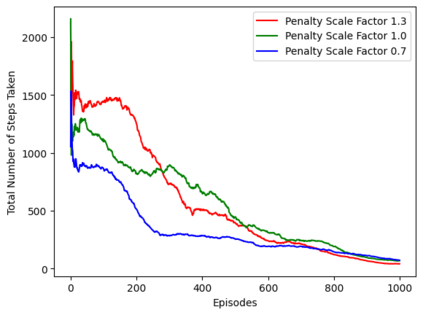
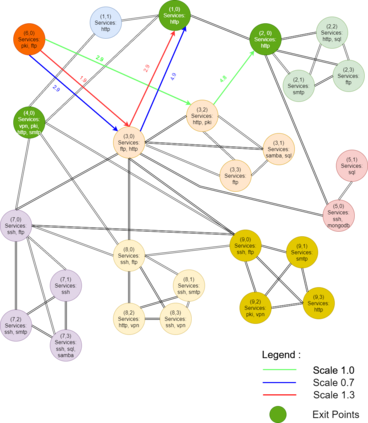
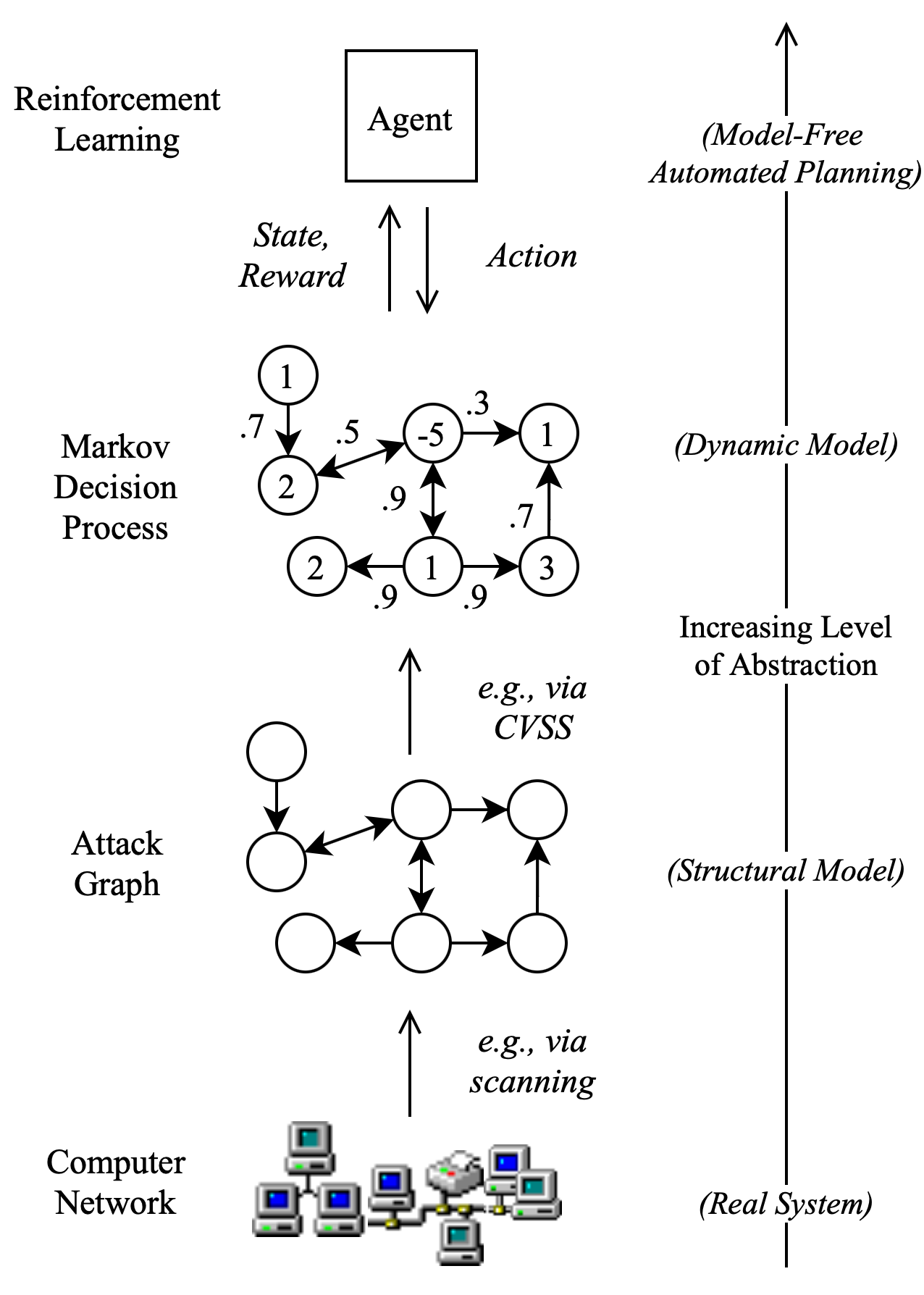
Reinforcement learning (RL), in conjunction with attack graphs and cyber terrain, are used to develop reward and state associated with determination of optimal paths for exfiltration of data in enterprise networks. This work builds on previous crown jewels (CJ) identification that focused on the target goal of computing optimal paths that adversaries may traverse toward compromising CJs or hosts within their proximity. This work inverts the previous CJ approach based on the assumption that data has been stolen and now must be quietly exfiltrated from the network. RL is utilized to support the development of a reward function based on the identification of those paths where adversaries desire reduced detection. Results demonstrate promising performance for a sizable network environment.
翻译:强化学习(RL),连同攻击图和网络地形,用于开发奖励和状态,确定企业网络数据过滤的最佳途径,这项工作以以前皇家珠宝(CJ)的识别为基础,重点是计算最佳途径的目标,对手可以绕过这些途径,损害CJ或附近东道主。这项工作推翻了以前的CJ方法,其依据假设是数据被盗,现在必须悄悄地从网络中流出。RL用来支持在确定对手希望减少探测的路径的基础上发展奖励功能。结果显示,在可测量的网络环境方面业绩良好。