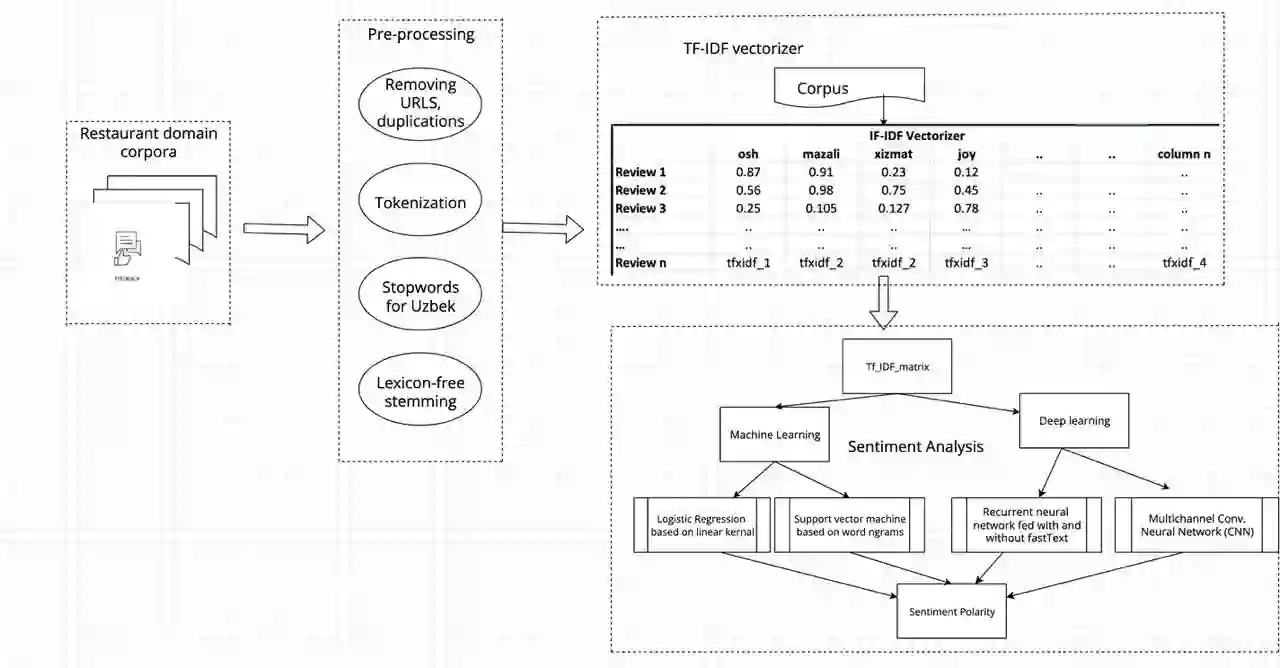
Extracting useful information for sentiment analysis and classification problems from a big amount of user-generated feedback, such as restaurant reviews, is a crucial task of natural language processing, which is not only for customer satisfaction where it can give personalized services, but can also influence the further development of a company. In this paper, we present a work done on collecting restaurant reviews data as a sentiment analysis dataset for the Uzbek language, a member of the Turkic family which is heavily affected by the low-resource constraint, and provide some further analysis of the novel dataset by evaluation using different techniques, from logistic regression based models, to support vector machines, and even deep learning models, such as recurrent neural networks, as well as convolutional neural networks. The paper includes detailed information on how the data was collected, how it was pre-processed for better quality optimization, as well as experimental setups for the evaluation process. The overall evaluation results indicate that by performing pre-processing steps, such as stemming for agglutinative languages, the system yields better results, eventually achieving 91% accuracy result in the best performing model
翻译:从大量用户产生的反馈(如餐馆审查)中提取用于情绪分析和分类问题的有用信息,这是自然语言处理的一项关键任务,这不仅是客户满意,可以提供个性化服务,而且能够影响公司进一步发展。在本文件中,我们介绍了收集餐馆审查数据的工作,作为乌兹别克语的情绪分析数据集,乌兹别克语是突厥语大家庭的一员,受到资源贫乏的严重影响,我们从大量用户产生的反馈(如餐馆审查)中提取了用于情绪分析和分类问题的有用信息,并对使用不同技术,从后勤回归模型到支持载体机器,甚至深层学习模型,例如经常性神经网络和进化神经网络等,通过评估而得出的新数据集进行了一些进一步分析。该文件详细介绍了如何收集数据、如何预先处理数据以提高质量优化,以及评估过程的实验性设置。总体评价结果表明,通过采取预处理步骤,例如为含蓄性语言而推出,系统将产生更好的结果,最终在最佳运行模型中取得91%的准确性结果。