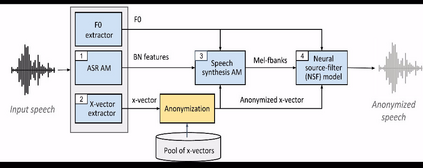
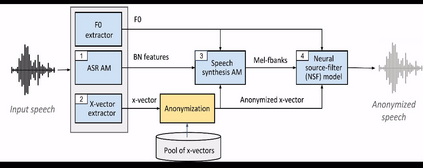
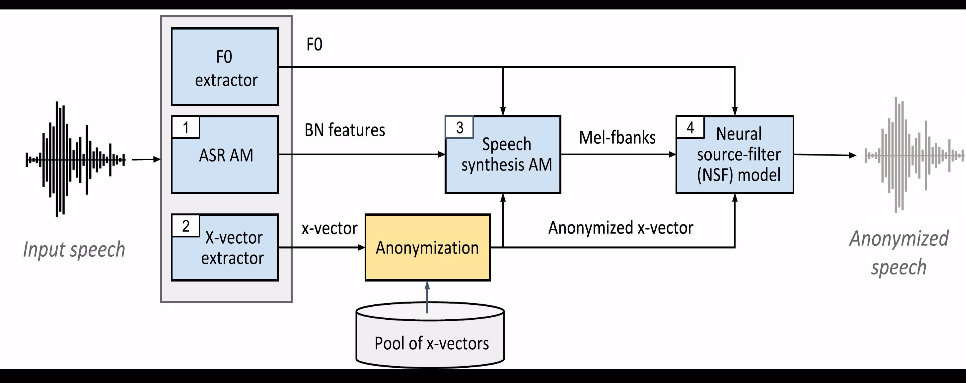
Speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns when speech data get collected. Speaker anonymization aims to transform a speech signal to remove the source speaker's identity while leaving the spoken content unchanged. Current methods perform the transformation by relying on content/speaker disentanglement and voice conversion. Usually, an acoustic model from an automatic speech recognition system extracts the content representation while an x-vector system extracts the speaker representation. Prior work has shown that the extracted features are not perfectly disentangled. This paper tackles how to improve features disentanglement, and thus the converted anonymized speech. We propose enhancing the disentanglement by removing speaker information from the acoustic model using vector quantization. Evaluation done using the VoicePrivacy 2022 toolkit showed that vector quantization helps conceal the original speaker identity while maintaining utility for speech recognition.
翻译:语音信号包含许多敏感信息,例如发言者的身份,这在收集语音数据时引起隐私问题。演讲者匿名的目的是转换语音信号,删除源演讲者的身份,同时不改变发言内容。目前的方法是通过依赖内容/声音脱节和语音转换来进行转换。通常,自动语音识别系统的声学模型会提取内容表述,而x-矢量系统则会提取发言代表。先前的工作显示,所提取的特征没有完全分解。本文将讨论如何改进特征分解,从而转换匿名发言。我们提议通过使用矢量四分法将演讲者信息从音响模型中去除,从而强化混乱状态。使用2022 VoicePrivacy 工具包进行的评估表明,矢量四分解有助于隐藏原发言者的身份,同时保持语音识别的实用性。