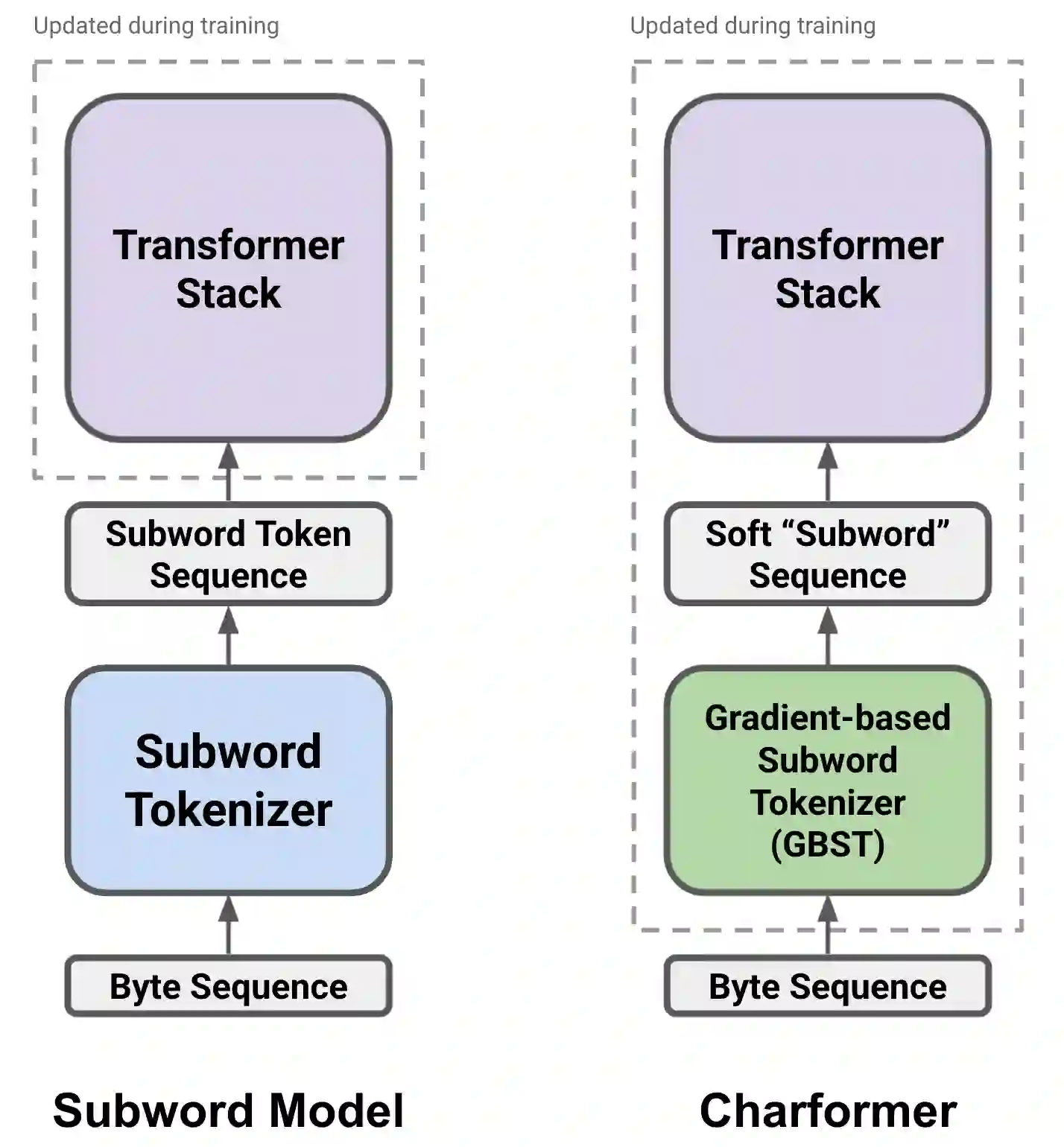
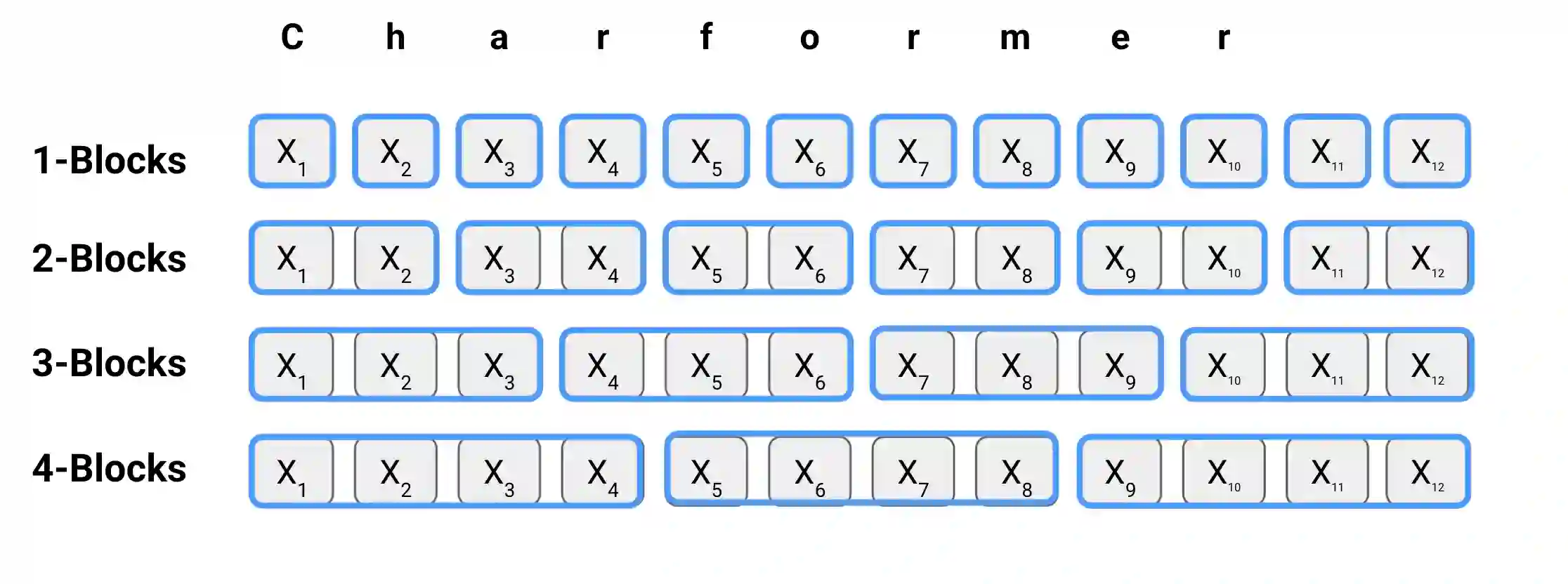
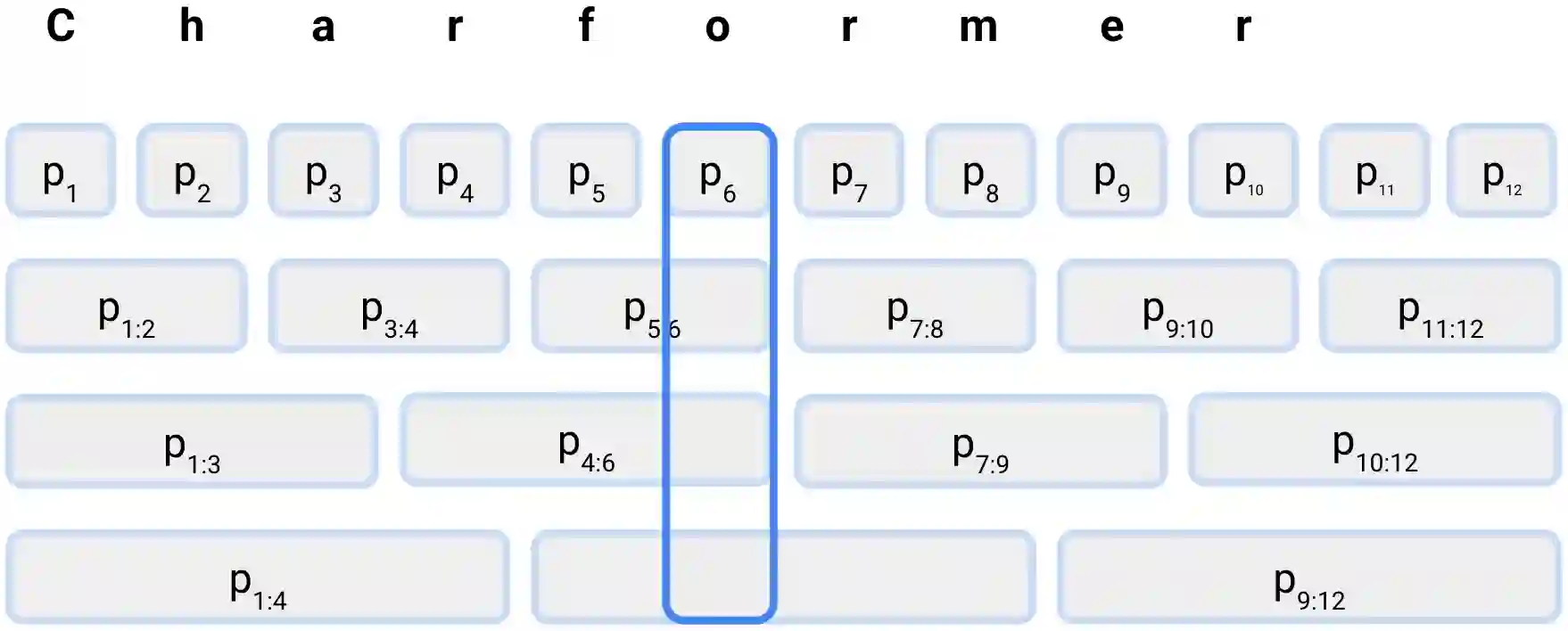
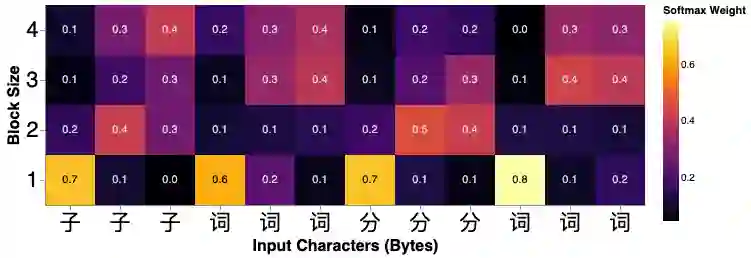
State-of-the-art models in natural language processing rely on separate rigid subword tokenization algorithms, which limit their generalization ability and adaptation to new settings. In this paper, we propose a new model inductive bias that learns a subword tokenization end-to-end as part of the model. To this end, we introduce a soft gradient-based subword tokenization module (GBST) that automatically learns latent subword representations from characters in a data-driven fashion. Concretely, GBST enumerates candidate subword blocks and learns to score them in a position-wise fashion using a block scoring network. We additionally introduce Charformer, a deep Transformer model that integrates GBST and operates on the byte level. Via extensive experiments on English GLUE, multilingual, and noisy text datasets, we show that Charformer outperforms a series of competitive byte-level baselines while generally performing on par and sometimes outperforming subword-based models. Additionally, Charformer is fast, improving the speed of both vanilla byte-level and subword-level Transformers by 28%-100% while maintaining competitive quality. We believe this work paves the way for highly performant token-free models that are trained completely end-to-end.
翻译:在自然语言处理中,最先进的自然语言模式依赖于不同的僵硬子字符号化算法,这种算法限制了其一般化能力和适应新设置的能力。在本文中,我们提议一种新的模型感化偏差,作为模型的一部分,学习子字符号化端到端。为此,我们引入一个基于软的梯度的子字符号化模块(GBST),以数据驱动的方式从字符中自动学习潜在的子字表达。具体来说,GBST列出候选子字块,并学习使用区块评分网络在位置上评分它们。我们还引入了Charexon,这是一种深层变异形模型,将GBST集成成并在字层操作。在英语GLUE、多语言和噪音文本数据集上进行广泛的实验,我们显示Charenter超越了一系列具有竞争力的字节级基线,同时通常以偏差和有时表现不佳的子字框模型进行演练。此外,Charrew是快速的,提高了香草小字级和子字级变换速度,我们完全相信28%的版本质量。我们完全相信以100的方式完成了。