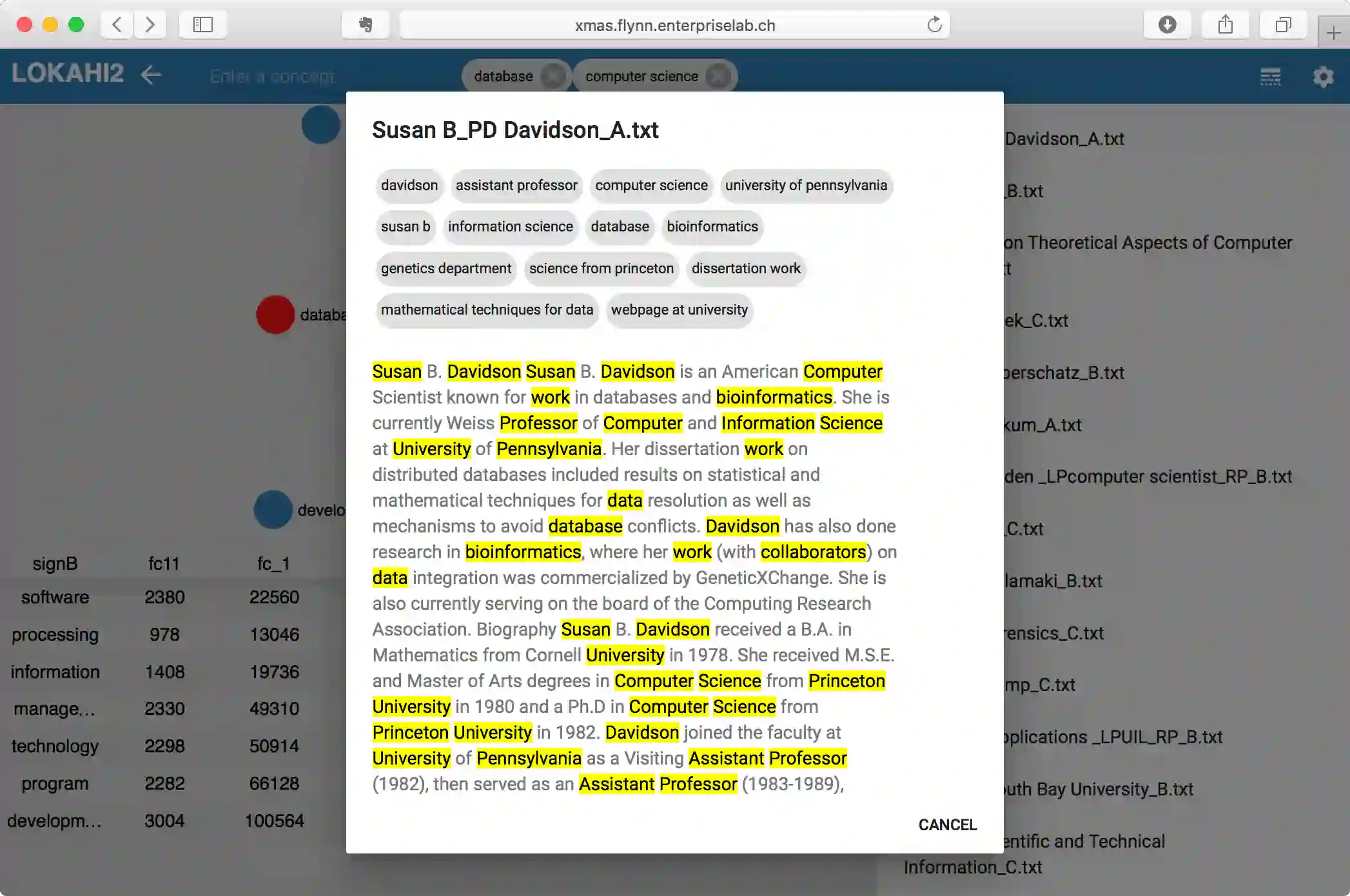
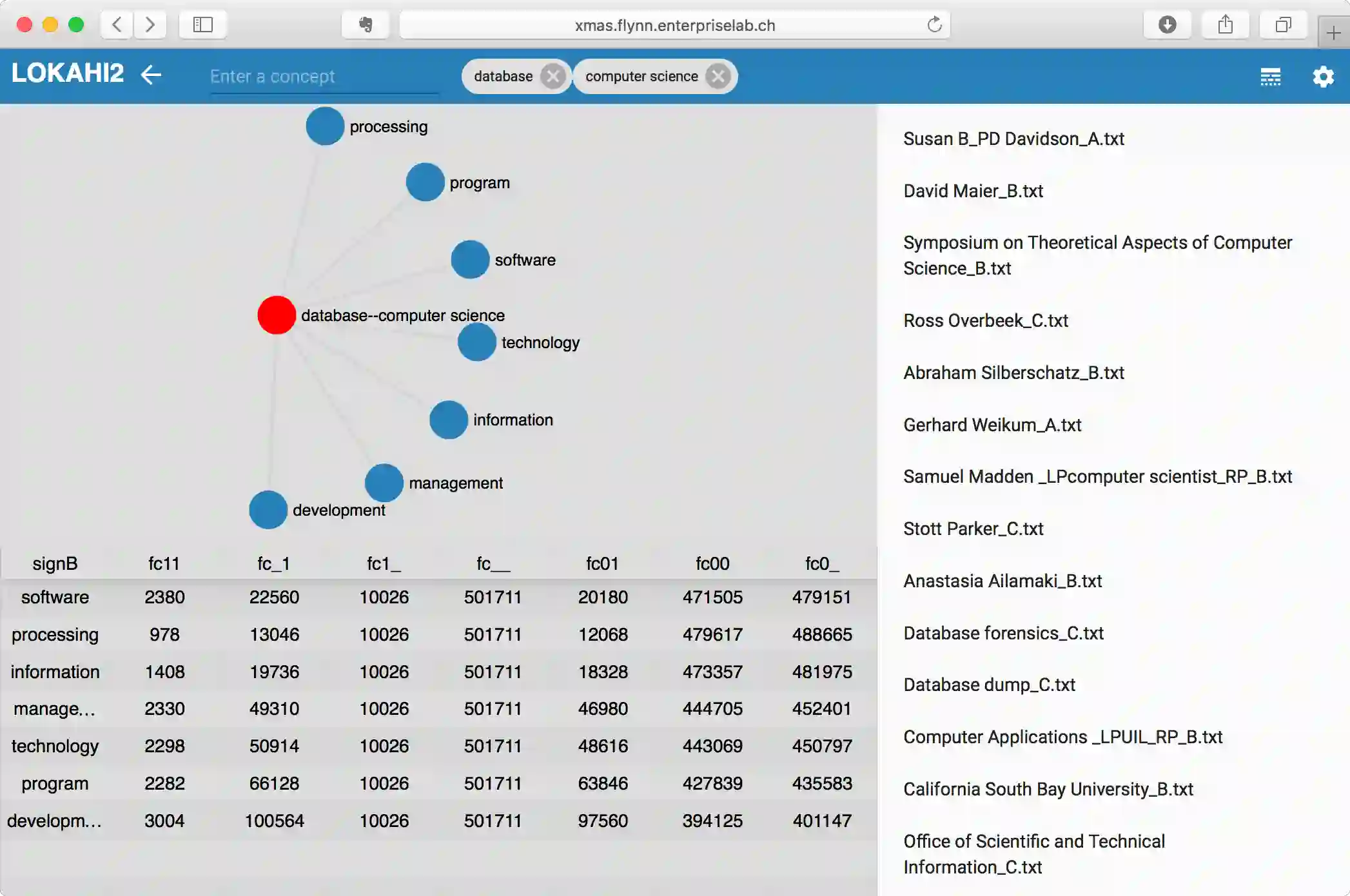
Entity relationship extraction envisions the automatic generation of semantic data models from collections of text, by automatic recognition of entities, by association of entities to form relationships, and by classifying these instances to assign them to entity sets (or classes) and relationship sets (or associations). As a first step in this direction, the Lokahi prototype can extract entities based on the TF*IDF measure, and generate semantic relationships based on document-level co-occurrence statistics, for example with likelihood ratios and pointwise mutual information. This paper presents results of an explorative, prototypical, qualitative and synthetic research, summarizes insights from two research projects and, based on this, indicates an outline for further research in the field of entity relationship extraction from text.
翻译:实体关系提取设想从收集文本中自动生成语义数据模型,通过对实体的自动识别,通过实体的关联形成关系,并通过对这些情况进行分类,将其划归实体组(或类别)和关系组(或协会),作为朝此方向迈出的第一步,Lokahi原型可以根据TF *IDF衡量标准提取实体,并根据文件级共同生成的统计数据产生语义关系,例如可能性比率和点对点的相互信息。本文介绍了一项探讨性、原型、定性和合成研究成果,总结了两个研究项目的见解,并在此基础上提出了在从文本中提取实体关系领域进一步研究的大纲。