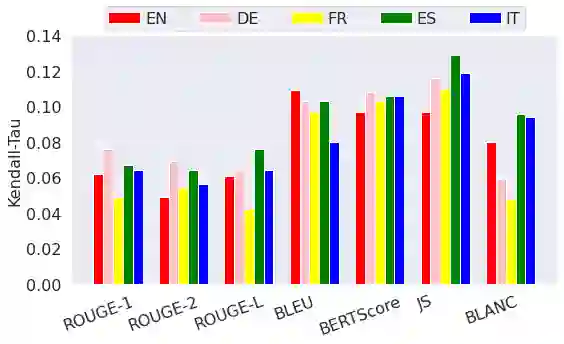
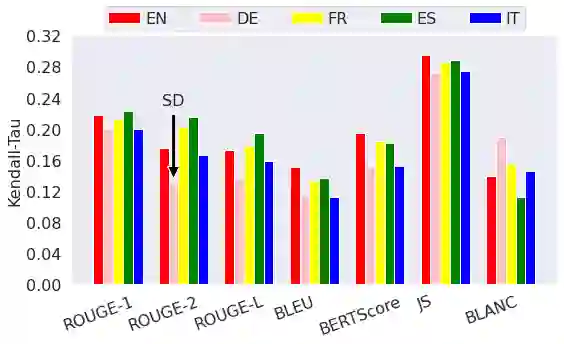
The creation of a large summarization quality dataset is a considerable, expensive, time-consuming effort, requiring careful planning and setup. It includes producing human-written and machine-generated summaries and evaluation of the summaries by humans, preferably by linguistic experts, and by automatic evaluation tools. If such effort is made in one language, it would be beneficial to be able to use it in other languages. To investigate how much we can trust the translation of such dataset without repeating human annotations in another language, we translated an existing English summarization dataset, SummEval dataset, to four different languages and analyzed the scores from the automatic evaluation metrics in translated languages, as well as their correlation with human annotations in the source language. Our results reveal that although translation changes the absolute value of automatic scores, the scores keep the same rank order and approximately the same correlations with human annotations.
翻译:制作大量综合质量数据集是一项相当、昂贵、耗时的工作,需要仔细规划和设置,包括制作人写和机器产生的摘要,由人(最好是语言专家)和自动评价工具对摘要进行评价。如果以一种语文进行这种努力,那么用其他语文使用这种数据将是有益的。为了调查我们能够多信任这种数据集的翻译而不重复用另一种语文的人类说明,我们将现有的英文汇总数据集(SummEval数据集)翻译成四种不同语文,分析了从翻译语文自动评价指标得出的分数及其与源语文人类说明的相关性。我们的结果显示,虽然翻译改变了自动分数的绝对价值,但分数保持与人手说明大致相同的顺序和相关性。