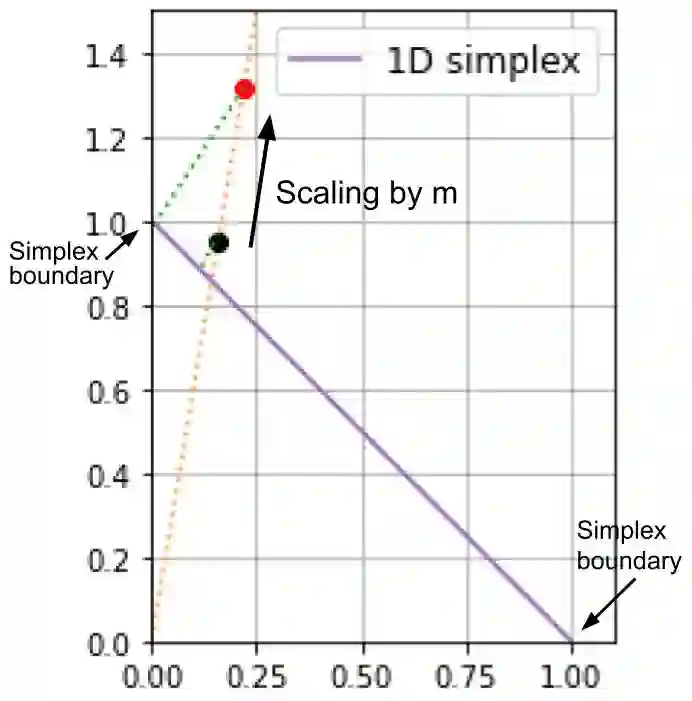
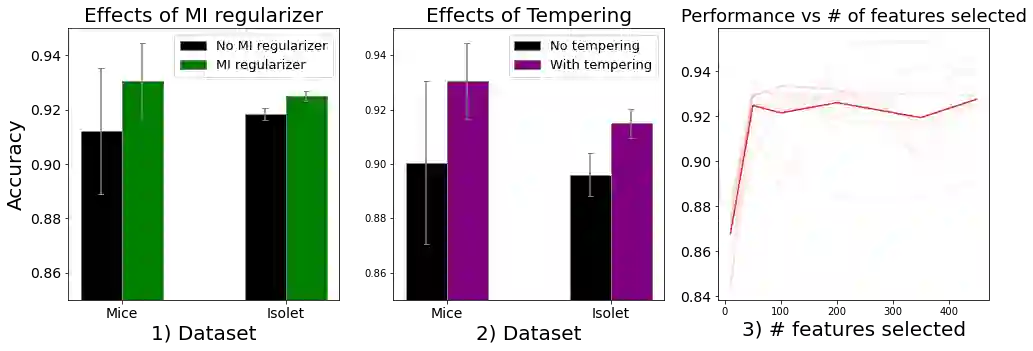
Feature selection has been widely used to alleviate compute requirements during training, elucidate model interpretability, and improve model generalizability. We propose SLM -- Sparse Learnable Masks -- a canonical approach for end-to-end feature selection that scales well with respect to both the feature dimension and the number of samples. At the heart of SLM lies a simple but effective learnable sparse mask, which learns which features to select, and gives rise to a novel objective that provably maximizes the mutual information (MI) between the selected features and the labels, which can be derived from a quadratic relaxation of mutual information from first principles. In addition, we derive a scaling mechanism that allows SLM to precisely control the number of features selected, through a novel use of sparsemax. This allows for more effective learning as demonstrated in ablation studies. Empirically, SLM achieves state-of-the-art results against a variety of competitive baselines on eight benchmark datasets, often by a significant margin, especially on those with real-world challenges such as class imbalance.
翻译:特征选择被广泛用于减轻训练过程中的计算要求,阐明模型的可解释性并提高模型的泛化能力。我们提出了 SLM - Sparse Learnable Masks,这是一种端到端的特征选择规范化方法,可以很好地缩放特征维度和样本数量。SLM 的核心在于一个简单但有效的可学习稀疏掩码,学习要选择哪些特征,并产生了一种全新的目标,可以从互信息的一次方程松弛中得出,该目标可以保证选择的特征和标签之间的互信息最大化。此外,我们推导了一个缩放机制,通过对 Sparsemax 的新颖使用来精确控制选择的特征数量。这使得在剔除了其他因素的情况下,SLM 的学习更具有效性。在 8 个基准数据集上,SLM 在多个具有挑战性的基准数据集上取得了可观的 state-of-the-art 结果,特别是在存在类别不平衡等实际问题的数据集上,其优势更加明显。