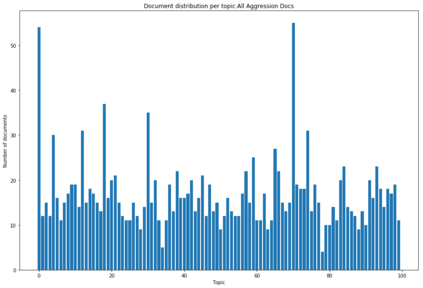
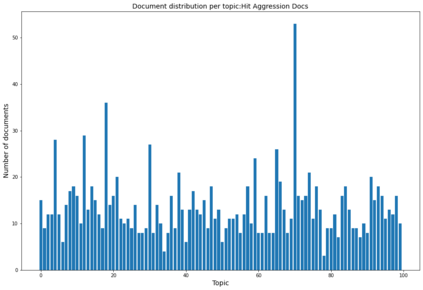
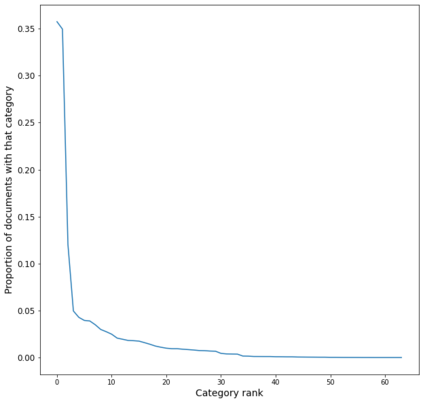
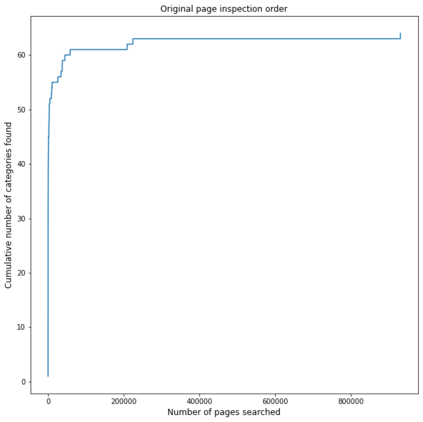
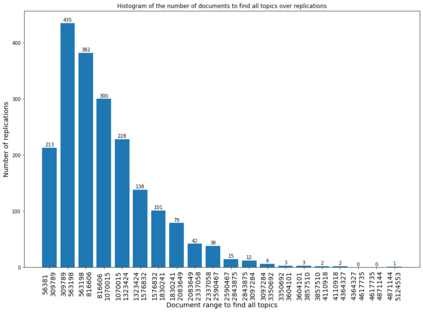
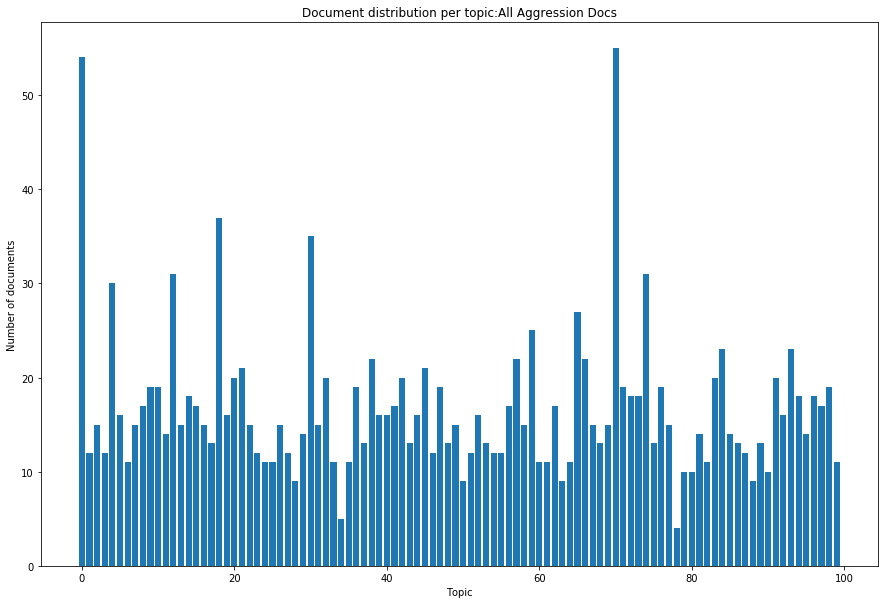
In the United States, the parties to a lawsuit are required to search through their electronically stored information to find documents that are relevant to the specific case and produce them to their opposing party. Negotiations over the scope of these searches often reflect a fear that something will be missed (Fear of Missing Out: FOMO). A Recall level of 80%, for example, means that 20% of the relevant documents will be left unproduced. This paper makes the argument that eDiscovery is the process of identifying responsive information, not identifying documents. Documents are the carriers of the information; they are not the direct targets of the process. A given document may contain one or more topics or factoids and a factoid may appear in more than one document. The coupon collector's problem, Heaps law, and other analyses provide ways to model the problem of finding information from among documents. In eDiscovery, however, the parties do not know how many factoids there might be in a collection or their probabilities. This paper describes a simple model that estimates the confidence that a fact will be omitted from the produced set (the identified set), while being contained in the missed set. Two data sets are then analyzed, a small set involving microaggressions and larger set involving classification of web pages. Both show that it is possible to discover at least one example of each available topic within a relatively small number of documents, meaning the further effort will not return additional novel information. The smaller data set is also used to investigate whether the non-random order of searching for responsive documents commonly used in eDiscovery (called continuous active learning) affects the distribution of topics-it does not.
翻译:在美国,诉讼当事人必须通过其电子存储的信息搜索其电子存储信息,以找到与具体案件相关的文件,并将其提供给对方。关于这些搜索范围的谈判往往反映出对某件事情会失手的恐惧(《失踪恐惧:FOMO》)。例如,回顾80%的水平意味着相关文件中有20%将未制作。本文提出这样的论点,即eDiscovery是识别反应性信息的过程,而不是识别文件。文件是信息的传递者;它们不是程序的直接目标。一个特定文件可能包含一个或多个专题或事实,而一个事实可能出现在不止一份文件中。质谱收藏家的问题、Heaps 法律和其他分析提供了从文件中查找信息的模式。在eDiscovery中,当事人不知道在收集或识别文件的概率中可能存在多少事实。本文描述了一个简单的模型,即估计一个事实会从所制作的数据集(所查明的数据集)中忽略一个或更多主题,而一个事实可能出现在一个非事实中。 质谱收藏者的问题、 使用两个数据集的单个样本将包含一个更小的缩序,然后用一个小的缩图解, 将用来分析一个小的序列中,然后用两个数据集显示一个小的序列中。