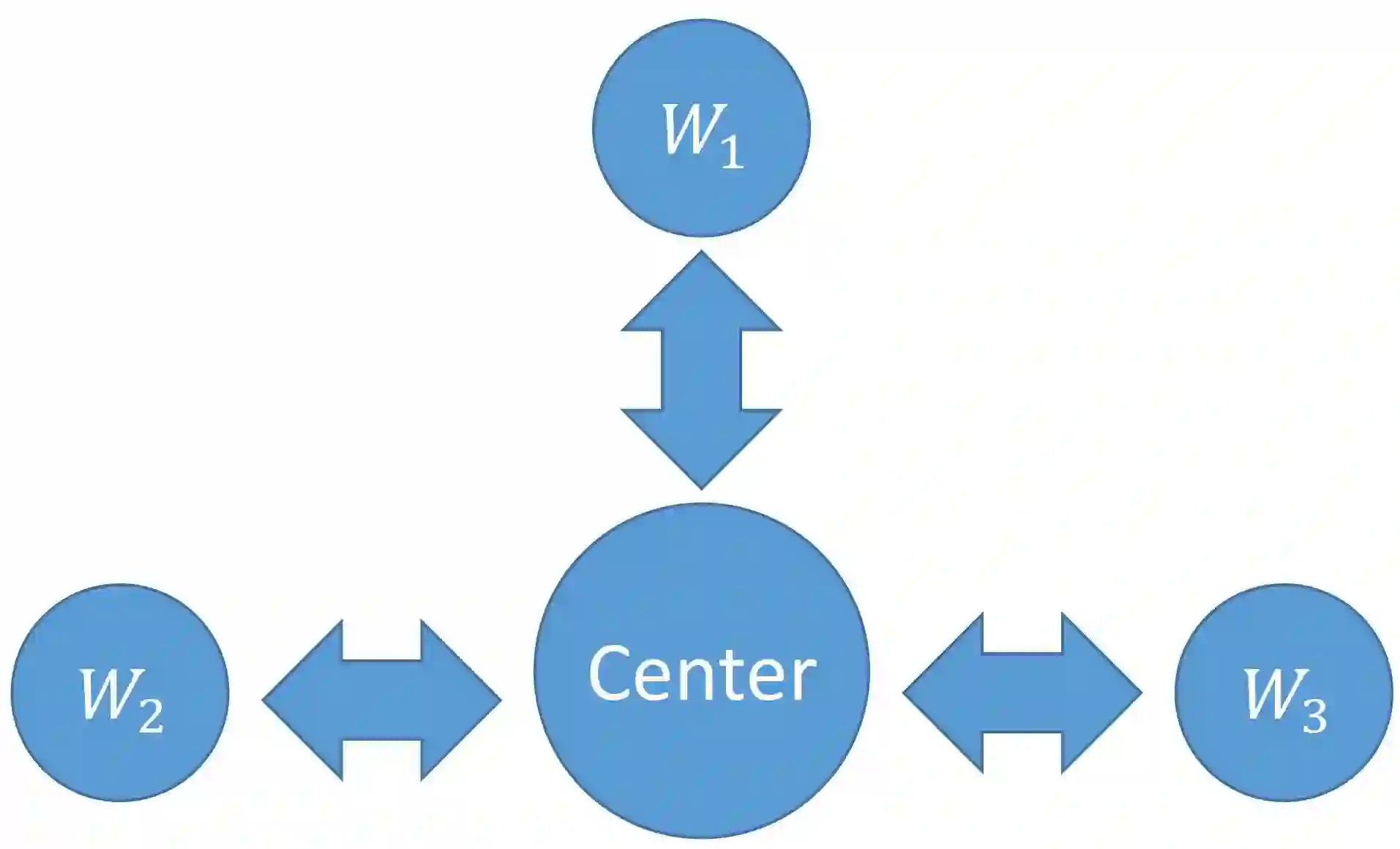
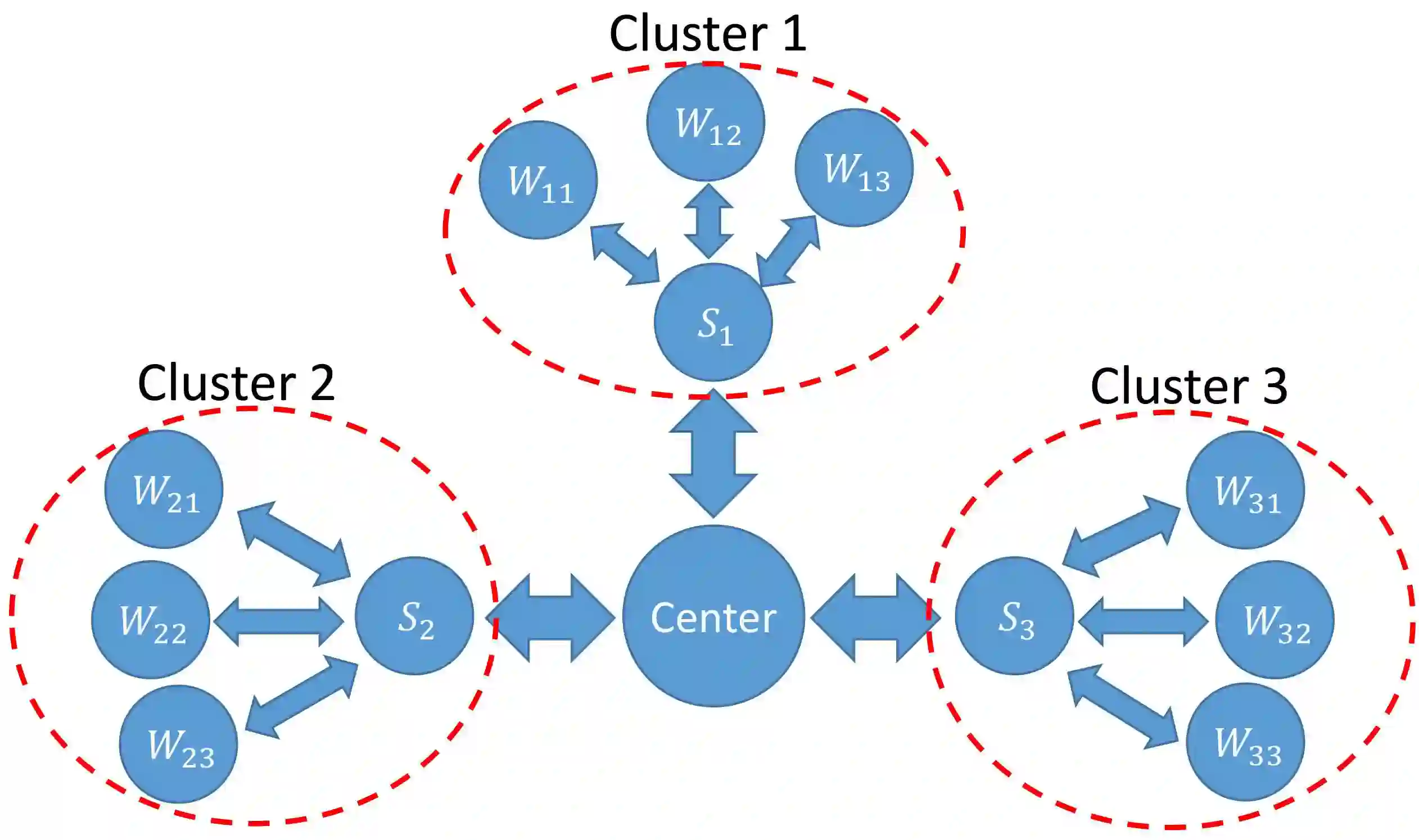
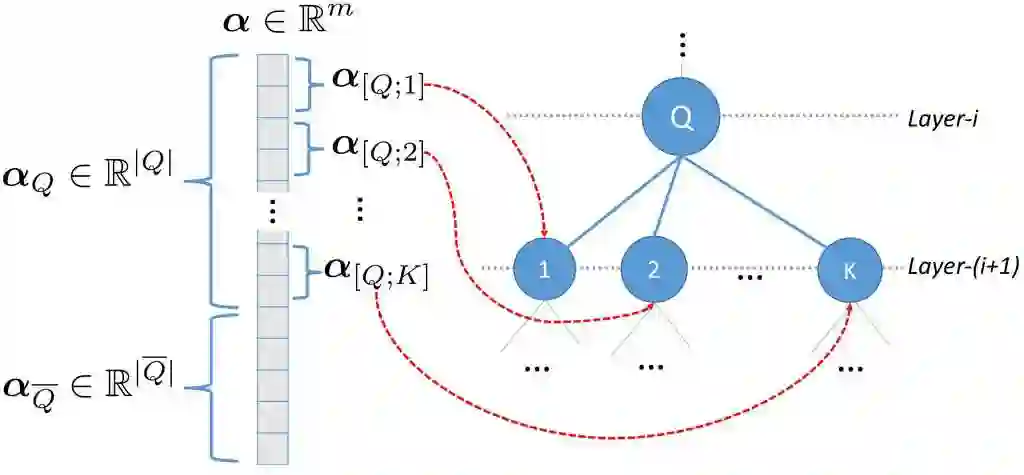
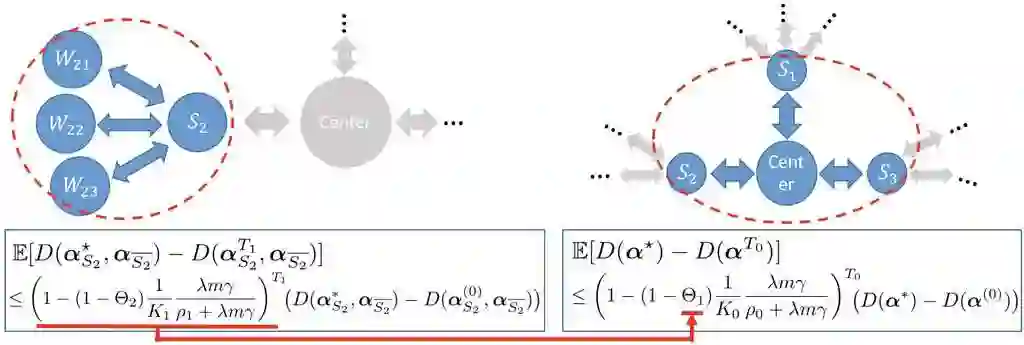
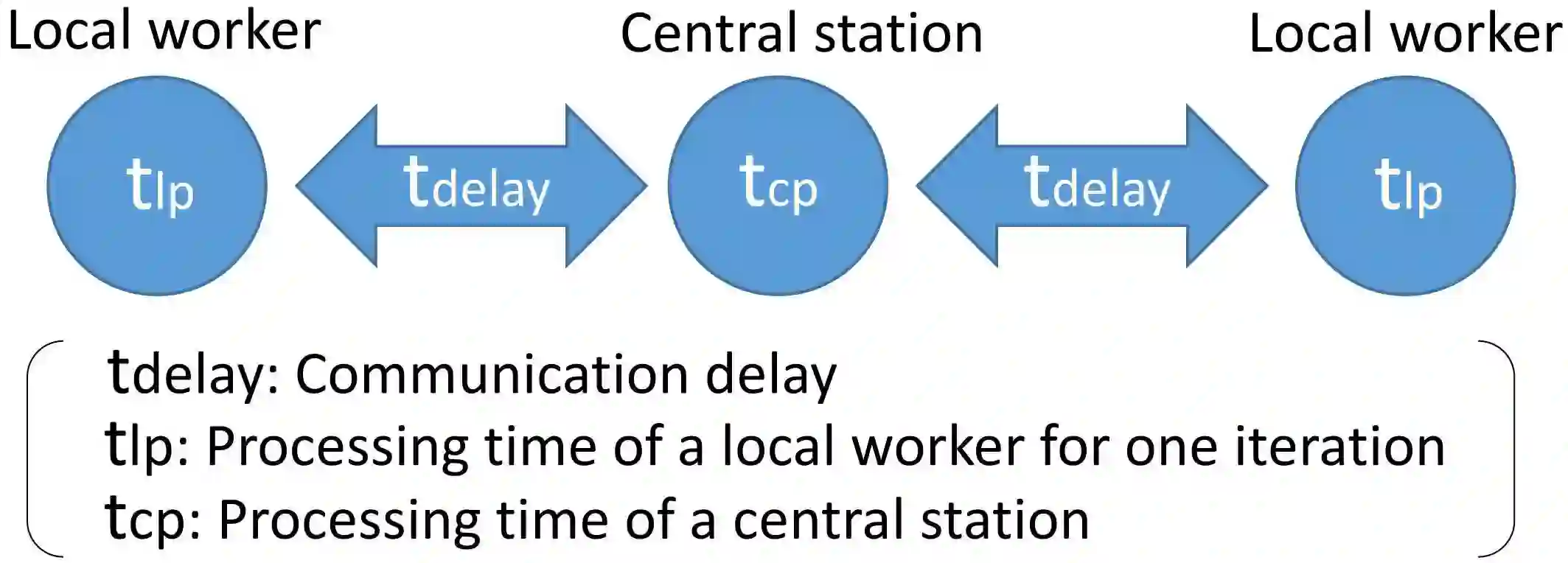
Due to the big size of data and limited data storage volume of a single computer or a single server, data are often stored in a distributed manner. Thus, performing large-scale machine learning operations with the distributed datasets through communication networks is often required. In this paper, we study the convergence rate of the distributed dual coordinate ascent for distributed machine learning problems in a general tree-structured network. Since a tree network model can be understood as the generalization of a star network model, our algorithm can be thought of as the generalization of the distributed dual coordinate ascent in a star network model. We provide the convergence rate of the distributed dual coordinate ascent over a general tree network in a recursive manner and analyze the network effect on the convergence rate. Secondly, by considering network communication delays, we optimize the distributed dual coordinate ascent algorithm to maximize its convergence speed. From our analytical result, we can choose the optimal number of local iterations depending on the communication delay severity to achieve the fastest convergence speed. In numerical experiments, we consider machine learning scenarios over communication networks, where local workers cannot directly reach to a central node due to constraints in communication, and demonstrate that the usability of our distributed dual coordinate ascent algorithm in tree networks. Additionally, we show that adapting number of local and global iterations to network communication delays in the distributed dual coordinated ascent algorithm can improve its convergence speed.
翻译:由于数据庞大,单一计算机或单一服务器的数据储存量有限,因此数据往往以分布方式储存。因此,往往需要利用通信网络的分布式数据集进行大型机器学习作业,通过通信网络进行分布式数据集的大规模机器学习作业。在本文件中,我们研究分布式双协调率对于分布式机器学习问题在一般树类结构型网络中分布式双协调率的趋同率。由于可以将树类网络模型理解为星类网络模型的普及性,因此,我们的算法可以被理解为分布式双协调在星类网络模型中的普及性双重协调。我们以循环方式提供分布式双协调率高于一般树类网络的趋同率,并分析网络对汇合率的影响。第二,我们通过考虑网络通信的延误,优化分布式双协调式的双重协调算法,以最大限度地加快其趋同速度。我们可以根据通信的延迟性选择本地循环的最佳数目,以达到最快的趋同速度。在数字实验中,我们考虑机器学习的情景,因为当地工人由于通信的制约而无法直接达到一个中心节点,并且分析网络对趋同率的影响。我们所分布式的双重协调式的网络可以改进其分布式计算方法,从而改进了我们分布式网络的网络的升级性。