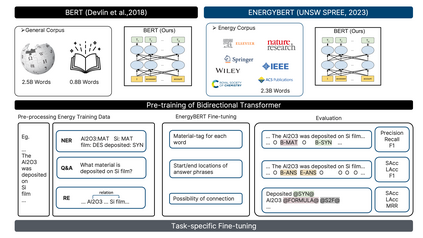
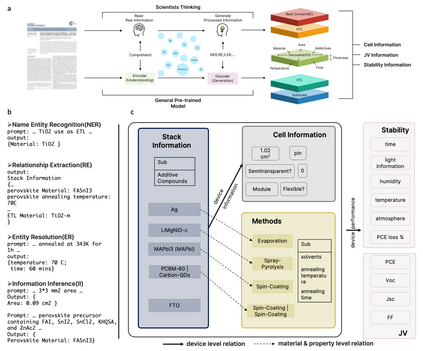
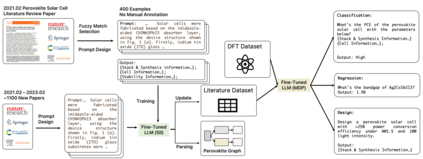
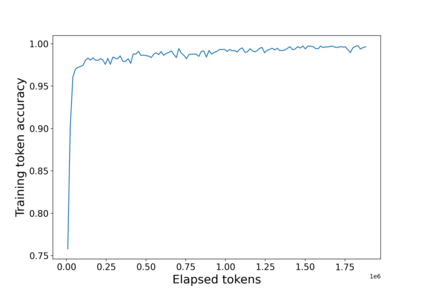
The amount of data has growing significance in exploring cutting-edge materials and a number of datasets have been generated either by hand or automated approaches. However, the materials science field struggles to effectively utilize the abundance of data, especially in applied disciplines where materials are evaluated based on device performance rather than their properties. This article presents a new natural language processing (NLP) task called structured information inference (SII) to address the complexities of information extraction at the device level in materials science. We accomplished this task by tuning GPT-3 on an existing perovskite solar cell FAIR (Findable, Accessible, Interoperable, Reusable) dataset with 91.8% F1-score and extended the dataset with data published since its release. The produced data is formatted and normalized, enabling its direct utilization as input in subsequent data analysis. This feature empowers materials scientists to develop models by selecting high-quality review articles within their domain. Additionally, we designed experiments to predict the electrical performance of solar cells and design materials or devices with targeted parameters using large language models (LLMs). Our results demonstrate comparable performance to traditional machine learning methods without feature selection, highlighting the potential of LLMs to acquire scientific knowledge and design new materials akin to materials scientists.
翻译:数据量在探索前沿材料方面具有越来越重要的意义,人工或自动化方法已经生成了许多数据集。然而,在应用学科中,材料的评估是基于其设备性能而不是其特性,材料科学领域难以有效利用数据的丰富性。本文提出了一种新的自然语言处理(NLP)任务,称为结构化信息推断(SII),以解决材料科学中设备级别信息提取的复杂性。我们通过调整GPT-3中的现有钙钛矿太阳能电池FAIR(可发现,可访问,可互操作,可重复使用)数据集来完成这项任务,获得了91.8%的F1分数,并扩展了自发布以来发表的数据。生成的数据格式化和标准化,使其可以直接用作后续数据分析的输入。此功能使材料科学家可以通过选择其领域内的高质量综述文章来开发模型。此外,我们设计了实验,使用大型语言模型(LLMs)预测太阳能电池的电气性能并设计具有定向参数的材料或设备。我们的结果表明,不需要特征选择,大语言模型具有获得科学知识和设计新材料的潜力,类似于材料科学家。