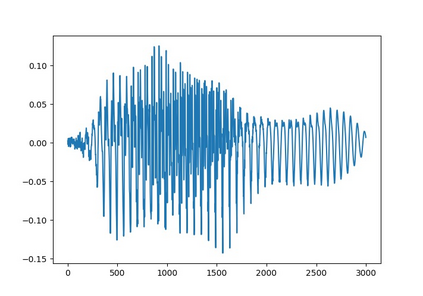
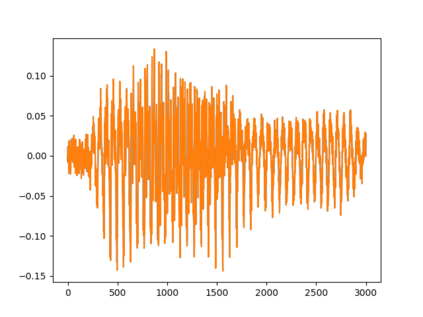
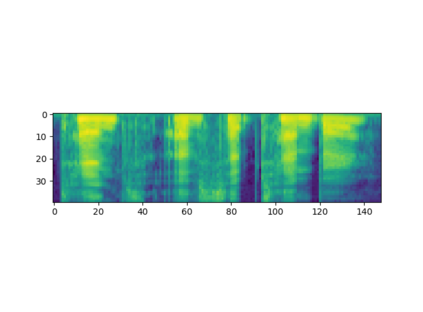
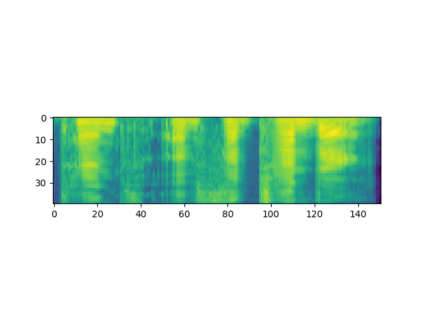
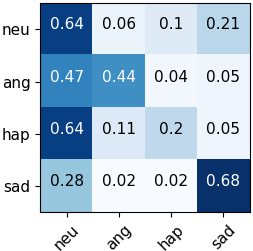
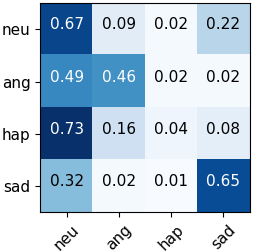
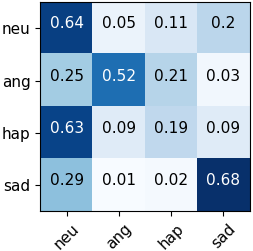
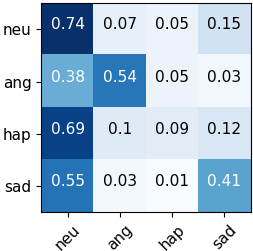
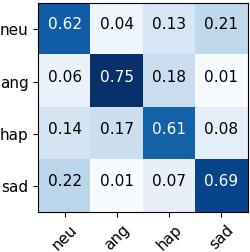
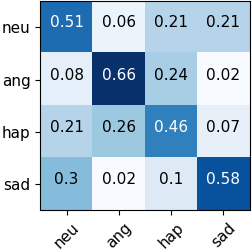
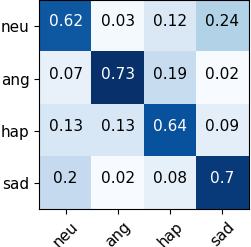
Automated emotion recognition in speech is a long-standing problem. While early work on emotion recognition relied on hand-crafted features and simple classifiers, the field has now embraced end-to-end feature learning and classification using deep neural networks. In parallel to these models, researchers have proposed several data augmentation techniques to increase the size and variability of existing labeled datasets. Despite many seminal contributions in the field, we still have a poor understanding of the interplay between the network architecture and the choice of data augmentation. Moreover, only a handful of studies demonstrate the generalizability of a particular model across multiple datasets, which is a prerequisite for robust real-world performance. In this paper, we conduct a comprehensive evaluation of popular deep learning approaches for emotion recognition. To eliminate bias, we fix the model architectures and optimization hyperparameters using the VESUS dataset and then use repeated 5-fold cross validation to evaluate the performance on the IEMOCAP and CREMA-D datasets. Our results demonstrate that long-range dependencies in the speech signal are critical for emotion recognition and that speed/rate augmentation offers the most robust performance gain across models.
翻译:语音中的自动情感识别是一个长期存在的问题。虽然早期情感识别工作依赖于手工艺特征和简单分类器,但外地现已采用深神经网络的端到端特征学习和分类方法。在采用这些模型的同时,研究人员还提出了几种数据增强技术,以扩大现有标签数据集的规模和变异性。尽管在实地做出了许多重大贡献,但我们仍对网络架构与数据增强选择之间的相互作用理解不足。此外,只有少数研究显示,多个数据集之间特定模型的可通用性,这是实现强健真实世界性业绩的先决条件。在本文中,我们对流行的深层学习方法进行了全面评估,以识别情感。为了消除偏见,我们利用VESUS数据集修补模型结构并优化超光度参数,然后用重复的5倍交叉验证来评价IEMOCAP和CREMA-D数据集的性能。我们的结果表明,语音信号的远程依赖性对于情感识别至关重要,而速度/速度增强能为各种模型带来最强的绩效收益。